אני יודע שזה בניגוד מוחלט לכל מה שמפתח BI או Data Engneer חולם עליו, אבל אנחנו הפסקנו להשתמש בספארק והדופ מזמן ואנחנו ממש לא מתגעגעים לזה.
יש לנו אין ספור דוגמאות מפרויקטים של הקמת פלטפורמות דאטה עם הדופ וספארק שפשוט לא הוכיחו את עצמם. בנקודה מסויימת היינו צריכים להחליט ברמת החברה האם אנחנו ממשיכים להילחם בזה בפרויקטים או משנים כיוון. על ההחלטה לחתוך אנחנו ממש לא מצטערים! בעיות כמו memory limit, over partitioning, זמני עיבוד לא יציבים ללא כל הסבר, בעיות concurrency, שבירת ראש על resource monitoring ועוד אין ספור בעיות שפשוט היו צריכות להעלם מהעולם מזמן. ארגון צריך להתעסק בדאטה ותוכן, לא בשטויות של טכנולוגיות שדורשות מומחים ומדעני טילים.
כדי לכתוב דוגמא ממשית, בחרתי את הפוסט הראשון שחוזר בגוגל על Join בין Datasets בספארק כדי להמחיש. בפוסט המפתח מסביר אין נכון לעשות Join בין טבלה של 3 מיליארד רשומות לטבלה של 1.5 מליון. ודוגמא אחרת לטבלה של 52 שורות. לאחר הרבה הסברים הוא מראה איך הוא מצליח להוריד את זמני הריצה של Count בין שתי הטבלאות מ-215 שניות ל- 61 שניות. ירידה של 71%(!) אין ספק שההסבר מספק וההצלחה גדולה, אם הייתי מפתח ספארק הייתי שמח ליפול על הפוסט הזה. אבל מה אם הפוסט הזה היה כתוב טיפה אחרת. מה אם הוא היה כותב לי ״הי, למה אתה ממשיך להשתמש בספארק אם כל כך מסובך לעשות Join בין טבלה גדולה לטבלה קטנה?״. או במילים אחרות ״חכם לא נכנס לבעיות שפיקח יכול לצאת מהן״.
זו התוצאה שהוא הגיע עם ספארק
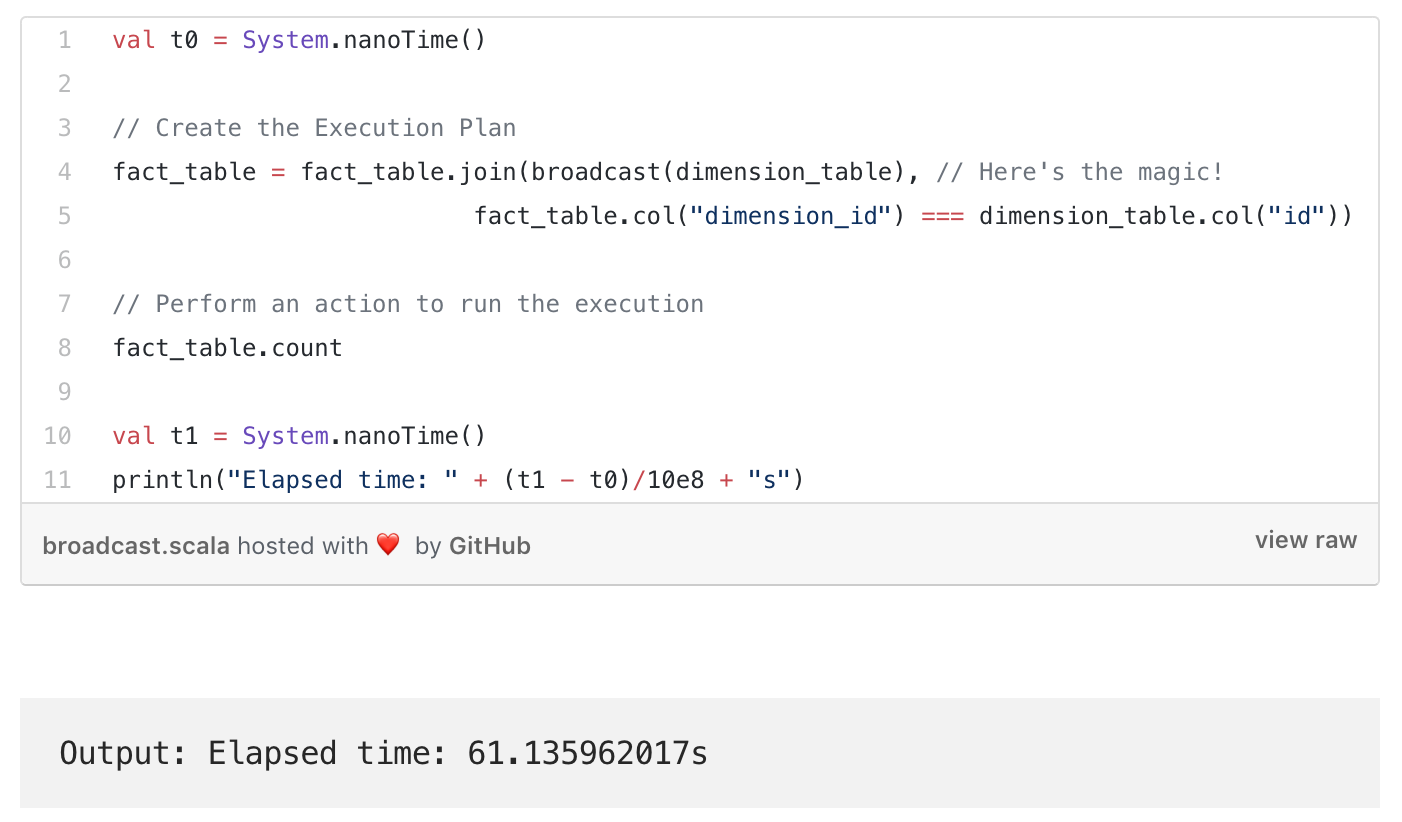
נזכיר מדובר על Join בין הטבלאות הבאות

Snowflake - בסיס נתונים As a Service
כדי להראות את ההבדל, בחרתי שתי טבלאות מבסיס הנתוני דמה של סנופלייק. וכדי לא לא להשאיר סימני שאלה, בחרתי שתי טבלאות גדולות יותר. טבלה של 6 מיליארד (במקום 3) עם Join לטבלה של 10 מליון (במקום 4). כלומר פי 2.
כתבתי שאילתא נאיבית ביותר עם Join פשוט. והוספתי Count Distinct, פעולה שהיתה בוודאות הורגת את Spark. זמני התגובה היו פי 2 יותר טובים מהשאילתא האופטימלית מהדוגמא בפוסט המדובר.
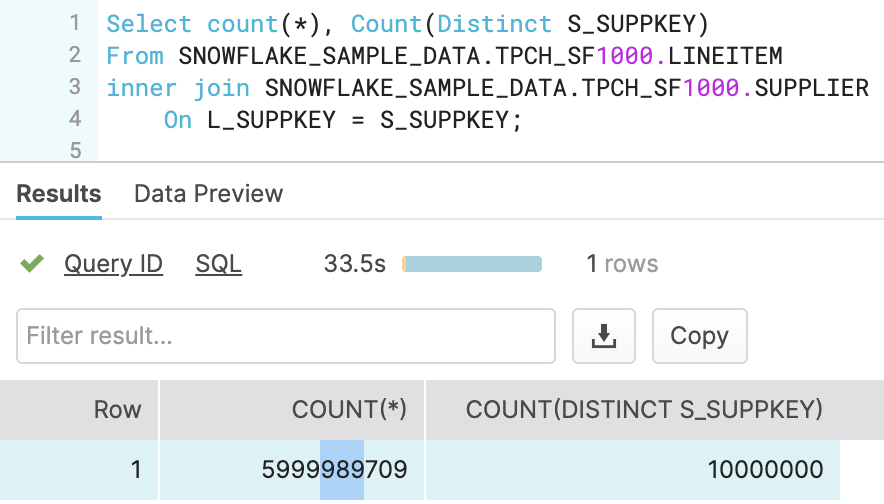
Scale
אחד היתרונות הבולטים בענן הוא היכולת להריץ תהליכים עם כוח עיבוד משתנה. סקיילאבילי. כמו שאפשר את ספארק, גם את השאילתא של סנופלייק העלתי מכוח של 8 קרדיטים לשעה (16$) ל-16 קרדיטים לשעה (32$). ואז התקבלה התוצאה תוך 18 שניות. חשוב לומר שבסוף השאילתא הורדתי את השירות חזרה ל-2$ לשעה. כך שהשאילתא עלתה בפועל רק 18 שניות, כלומר $0.16.
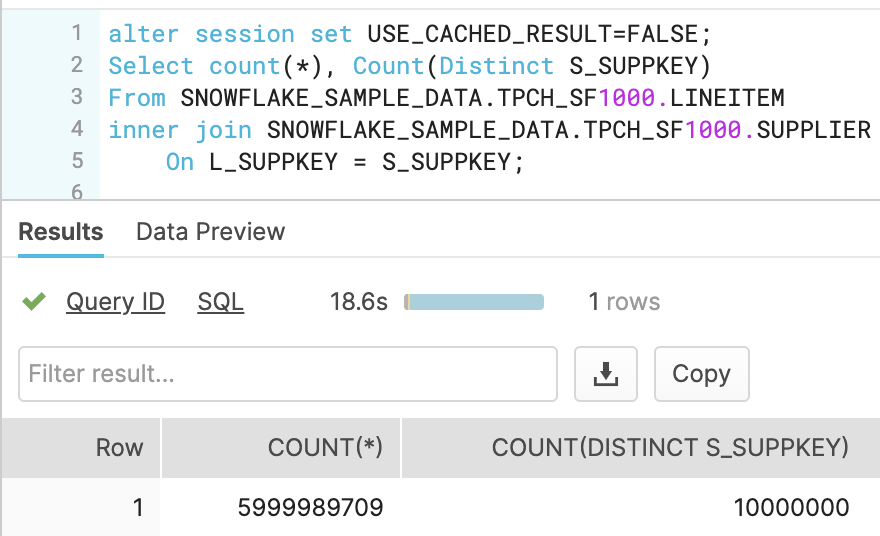
ואם נריץ את אותה שאילתא ללא ה-Distinct הכבד יחסית, נגיע לתוצאה של 10 שניות!
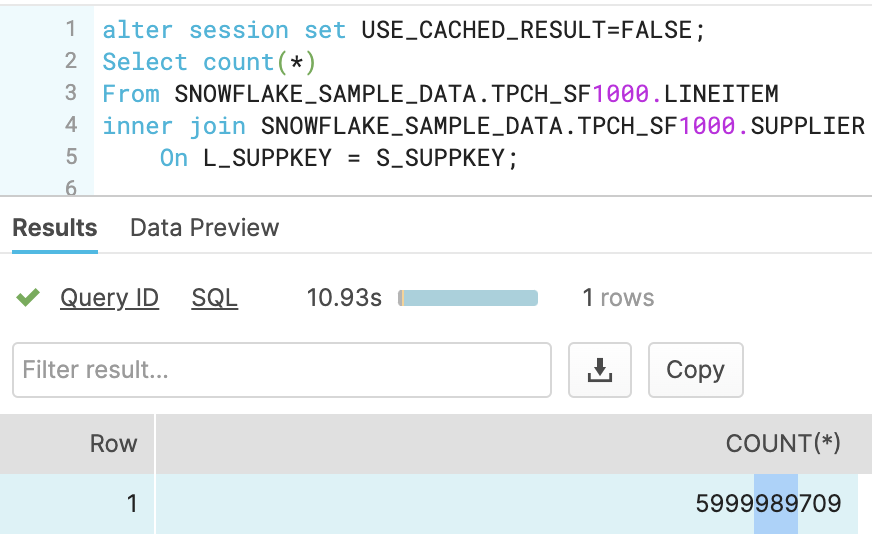
שימו לב! זו לא השוואה בין הטכנולוגיות! זו רק דוגמא כדי להמחיש כמה דבר שדורש הסברים ואופטימיזציה בצד אחד, ניתן למימוש נאיבי ללא כל מאמץ בטכנולוגיה אחרת. אין לי ספק שאפשר למצוא מצבי קצה שהם המצב הפוך, אבל להערכתי ב-99% מהמקרים זו תהיה התוצאה.
הערה II - לקחנו כאן רק דוגמא של Join, ישנן דוגמאות אחרות כמו כתיבה של נפחים גדולים לטבלה, מגבלה של זיכרון על ה-Node ועוד מספר רב של אתגרים שתתקלו בהן בדרך. זה לא שבסנופלייק ו-BQ אין אתגרים, אבל לרוב מדובר בהרבה פחות וכאלו שניתנים לפתרון מהיר מאד באמצעות SQL.
השוואת עלויות?
לא כתוב בפוסט של ספארק באיזה כוח עיבוד הוא הריץ את השאילתא. אבל זה ממש לא חשוב. הרבה לפני שאתם בודקים את עלויות החומרה תבדקו את מהירות הפיתוח. הבחור כנראה ישב כמה שעות כדי לעשות אופטימיזציה? זה מספיק כדי להבין שספארק יקר פי כמה וכמה.
לא רק סנופלייק
מי שהתחיל את מהפיכת בסיסי הנתונים המנוהלים היו דווקא גוגל עם ה-Big Query. בעשור האחרון עשינו לא מעט פרויקטים בהדופ בסביבות אמזון (EMR) ובסביבת מיקרוסופט (HdInsight), אבל על בגוגל (עם ה-Data proc) מעולם לא יצא לנו. מדוע? פשוט מאד, כשיש בסיס נתונים מנוהל שיודע לתמוך בעיבוד של ה-Raw Data, הטכנולוגיה הזו כמעט ומאבדת מכל הערך שלה. אתם שואלים אם היא תשרוד, אם אני צריך לנחש הייתי אומר שלא, היא תעלם. אבל זה לא יקרה מחר בבוקר, שכן יש עדיין בנקים וחברות בטחוניות שעדיין לא יכולות לעבור לענן ועבורן זה הפתרון היחיד שקיים. ומדוע סנופלייק כן, עד היום בענן של AWS ובענן של Azure לא היה פתרון אחיד שיכול לשמש גם לאחסון ותחקור של ה-Raw Data, גם למחסן נתונים וגם עם ביצועים מעולים וסנופלייק הוא בדיוק כזה.
ומה עם ספארק?
אמרנו בהתחלה להפסיק להשתמש בספארק, אז תרשו לנו לדייק את זה. ספארק זו שפה גנרית המשמשת עוד הרבה תחומים בעולמות הדאטה. אנשי data science משתמשים בה לאנליטיקה, היא ניתנת לשילוב עם פייתון, ג׳אווה, R וכו׳, היא משתמשת לעיבוד Stream ועוד. להלן גוגל טרנד בהשווה להדופ (ספארק באדום):
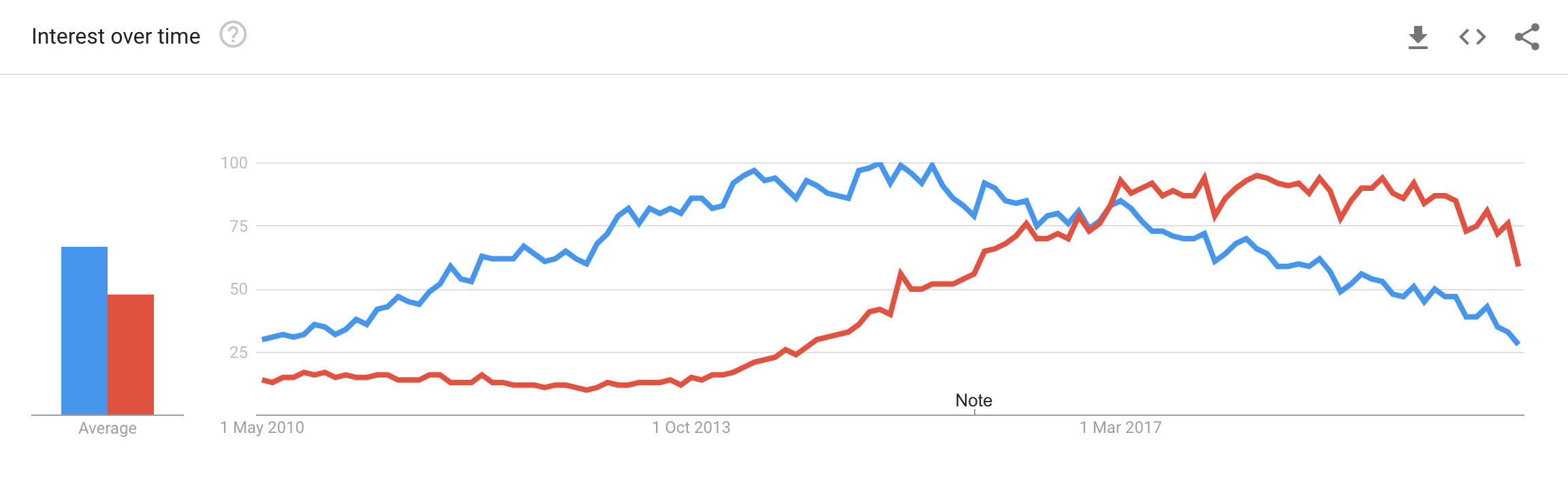
במילים אחרות, אין לנו שום דבר נגד ספארק, אך כשמדובר ב-Data pipeline ו-ELT, לרוב SQL פשוט יעשה את העבודה בקלות רבה יותר לפיתוח ותחזוקה.