בתקופה זו, בה כולנו מוצפים בגרפים ונתונים על הקורונה (ולפני כן, על הבחירות) חשוב לשים דגש על התפקיד אולי החשוב ביותר בתחום הדאטה בארגון, תפקיד ה data engineer.
אתרי הדרושים מפוצצים בטייטלים מגוונים ומרשימים. אז תרשו לנו לעשות לכם סדר ולתמצת את זה לשלושה תפקידים מרכזיים. בואו נבין מהם, מה תפקידו של כל אחד ובאילו כלים הוא משתמש.
שתי מילים על Vision.bi ומאיפה אנחנו באים. הוצאנו לפועל מעל 150 פרויקטים להקמת פלטפורמות דאטה, אנחנו נושמים את הטכנולוגיות השונות מאז 2007 ושואפים לאורך כל השנים להוביל עם הטכנולוגיות המתקדמות ביותר. בחברה מועסקים כ-50 מהנדסים ממגוון התפקידים בתחום הדאטה ומכאן ההיכרות והצורך בהגדרת הדרישות והציפיות מכל תפקיד.
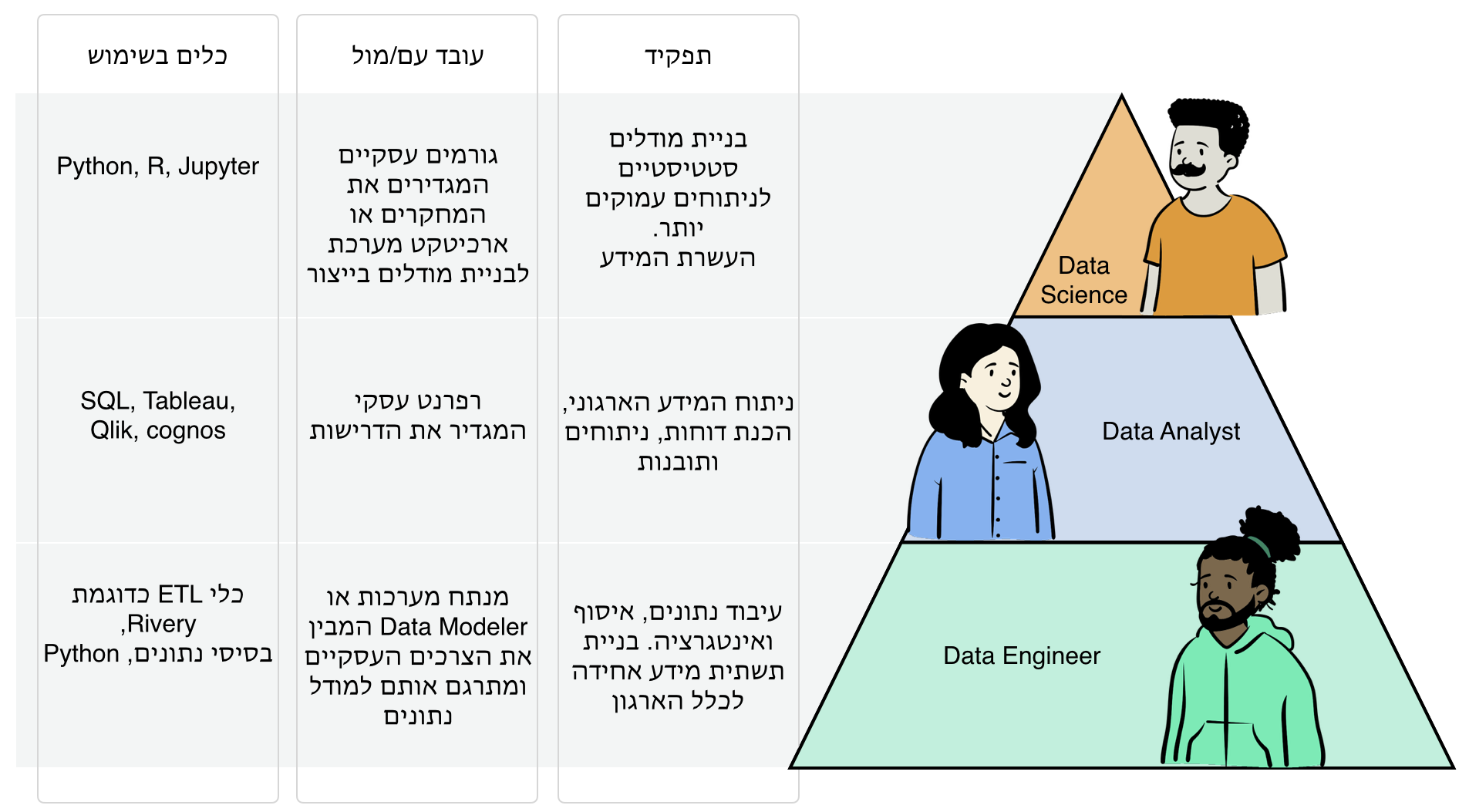
אם כך בעולמנו יש שלושה תפקידים מרכזיים: data engineer, data analyst ו- data science. קיימים מסביב עוד מספר תפקידים כמו מנתח מערכות, רפרנט עסקי וכד', אבל אנחנו נתמקד ב hands-on וסביבם נבנה את האחרים.
במהלך הניתוח שעשינו על נתוני הקורונה, לצורך המחשה, קיבלנו מידע ממקורות שונים והיינו צריכים להחליט מה עושים איתם. מכניסים אותם לבסיס נתונים או מעבירים אותם כמו שהם לאנליסטים כדי שיחקרו את המידע? במידה וניתן אותם כמו שהם ל data science או ל data analyst הם יצטרכו לעשות לא מעט עיבוד למידע לפני ניתוח הנתונים. למשל הם יצטרכו לנרמל את הנתונים לגודל אוכלוסיה, הם יצטרכו לחבר מקורות שונים לציר הזמן וגודל האוכלוסיה, להעשיר את המידע ופעולות נוספות ולבסוף הם יצטרכו לדאוג שהמידע יהיה מסונכרן ויתעדכן אחת ליום או אפילו יותר מזה. כל זאת לפני שביקשנו מהם להתמודד עם נפחים קצת יותר גדולים או עם פורמטים קצת יותר מורכבים מ-CSV או טבלה. במילים אחרות הכנסנו את האנליסט והחוקר לבעיה שאין לאף אחד מהם את הכלים להתמודד איתה. מכאן נובע הצורך הבסיסי והראשוני במומחה בהקמת תשתית מידע והוא ה-Data engineer.
התפקיד
תפקידו של data engineer הוא לדעת להתחבר למקורות נתונים שונים, כגון בסיסי נתונים, קבצים, API. למשוך אותם בצורה נכונה ויעילה, למשל למשוך רק שינויים, להכיר את מבנה הנתונים במקור ולבסוף לדעת איך לחבר את הנתונים עם מודל הנתונים הקיים. יש כאן data modeling המותאם לצרכי התחקור העיסקי, אינטגרציה של נתונים בגרנולריות שונה, הבנה של מפתחות וקשרים בין data sets ועוד המון תחומים טכניים כאלה ואחרים הקשורים בדאטה. ה data engineer עובד עם בסיסי נתונים ועם כלי אינטגרציה (ELT). ישנן תחומים בהם יש צורך גם בטכנולוגיות משלימות כמו פייתון, ספארק וכד', אבל לרוב השאיפה להשאר בשפת SQL סטנדרטית.
התוצר של אותו data engineer הוא תשתית דאטה (לרוב בסיס נתונים) אליה יתחברו ה data analyst וה data science.
מדוע אתם חייבים את השלב הזה?
ניהול הלוגיקה העסקית במקום מרכזי - אחת הטעויות הנפוצות ביותר בארגונים שרק נכנסים לתחום היא כתיבת לוגיקות עסקיות בכלי פרונט על ידי data analyst. זוהי טעות מהמון סיבות, נמנה רק חלק מהן:
- חלק ממקורות המידע אינם פשוטים להתממשקות הנאיבית של כלי הדוחות. למשל משיכת נתוני Salesforce , netsuit או כל API אחר.
- כל משתמש יכול לסדר את המידע איך שנראה לו ולעולם לא תהיה הסכמה על הנתונים.
- המידע העסקי החשוב, לאחר העיבוד, "כלוא" בטכנולוגיה שאינה פתוחה לכלים אחרים (להבדיל מבסיס נתונים למשל)
- לאחר משיכת הנתונים תמיד נדרש קצת לשנות אותם כדי להצליב עם מידע אחר, לרוב כלי בפרונט אינם מתאימים לזה ואינם סקיילבילים
- לא ניתן/מורכב לפתח במקביל.
- קשה מאד להריץ תהליכי בקרה
- ועוד ועוד
סדר וארגון - גם אם יש לכם פונקציה אחת בארגון שעושה הכל, השכבות הללו חייבות להבנות בצורה מתודולוגית. ראשית יש לסדר את הנתונים בבסיס הנתונים, לתזמן אותם, לתזמן בדיקות וולידציה ורק לאחר מכן להתמקד בניתוח במידע.
שפה אחידה - בהמשך ל-1, במהלך עיבוד המידע מתקבלות עשרות החלטות והנחות עבודה, החלטות אלו לא יכולות להיות שמורות ברמת התצוגה בלבד. ניקח למשל את המרחק של כל מדינה ממועד שיא ההתפרצות המחלה. במודל הנתונים שיא המחלה נבחר לפי ממוצע נע. זהו נתון שחייב להישמר בבסיס נתונים ולא בכלי התצוגה, שכן מחר יתחבר אנליסט אחר וירצה גם להשתמש באותו נתון הוא יהיה זמין. רק כך יוצרים שפה משותפת בארגון.
שלמות המידע - לצד זה שאנחנו מקבלים נתונים נרצה לא מעט פעמים לשלב את זה עם נתונים שאנחנו משלימים. זהו מקור נתונים נוסף שצריך לשבת בתשתית שיהיה זמין לכולם, ולא אצל האנליסט עבור הדוח הבודד.
במילים אחרות, הרבה לפני שמכנסים את הנתון הראשון לכלי הדוחות, נדרשת עבודת הכנה. מתי אפשר לדלג על השלב הזה? כאשר רוצים לעשות ניתוח מקרה פרטי, עבודת מחקר חד פעמית על מידע סטטי, לנסות לענות על שאלה עסקית. במצב כזה, זה לגיטימי לא להיות תלויים בצוות תשתיות המידע ולאפשר למשתמשים לעשות את הניתוחים שלהם. אבל זה בתנאי שאנחנו לא מצפים מהם (1) לעשות אינטגרציות מורכבות (2)לתזמן את התהליך שימשיך להתרענן בתדירות מסויימת (3)דורשים מהם לעבד את המידע ולשתף את התוצאות עם משתמשים אחרים שגם יוכלו לבנות דוחות משלהם או בקיצור, כל זמן שאנחנו לא מבקשים מהם ליצור תשתיות מידע. הרבה פעמים התוצרים של המחקרים הללו חוזרים כבקשה להעשרת המידע מצוות התשתיות, כדי שיהיו זמינים לכולם.
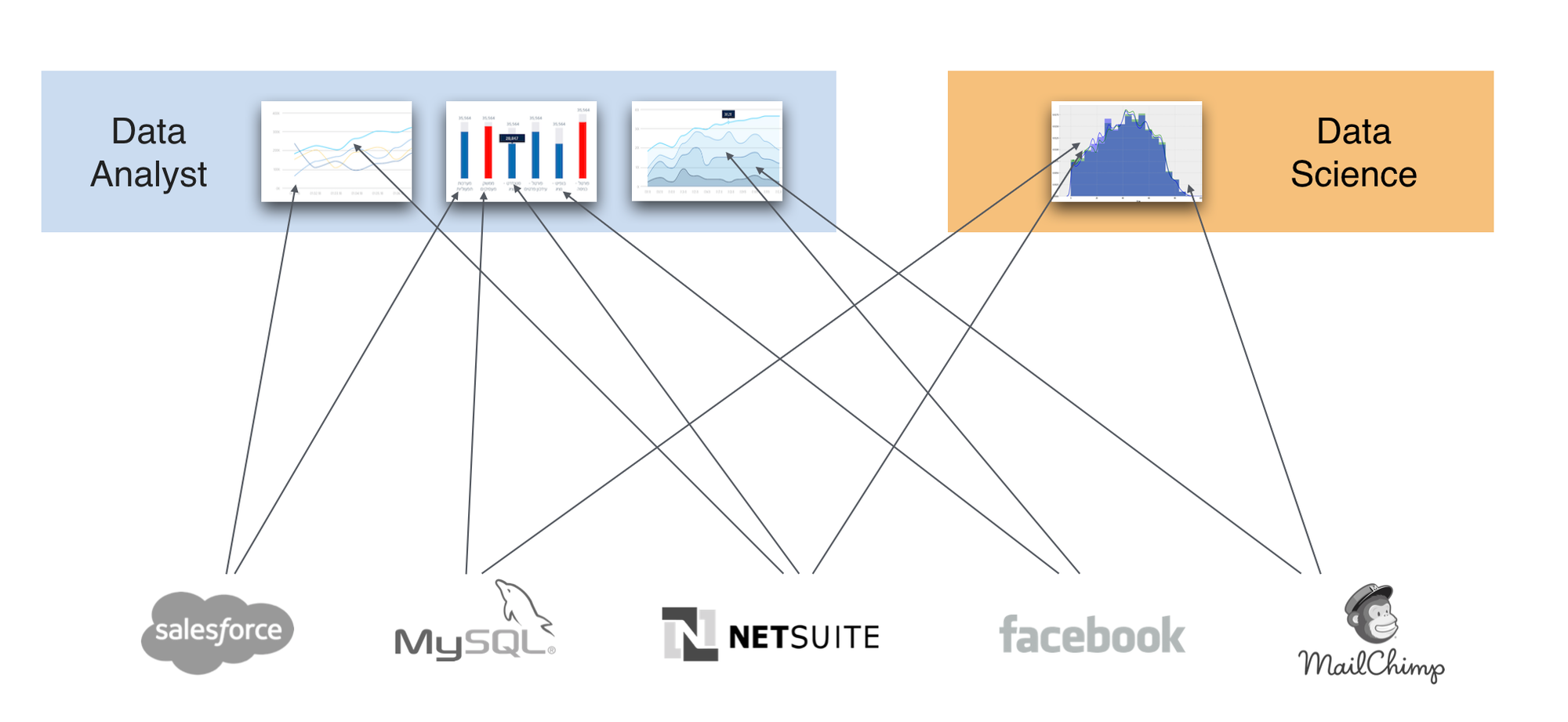
ארגון ללא DE
כך יראה ארגון ללא Data Engineer. נתונים לא אחידים בין הדוחות (לוגיקות שונות, סנכרון נותנים לא אחיד, קושי רב בחיבוריות לנתונים השונים ועוד.
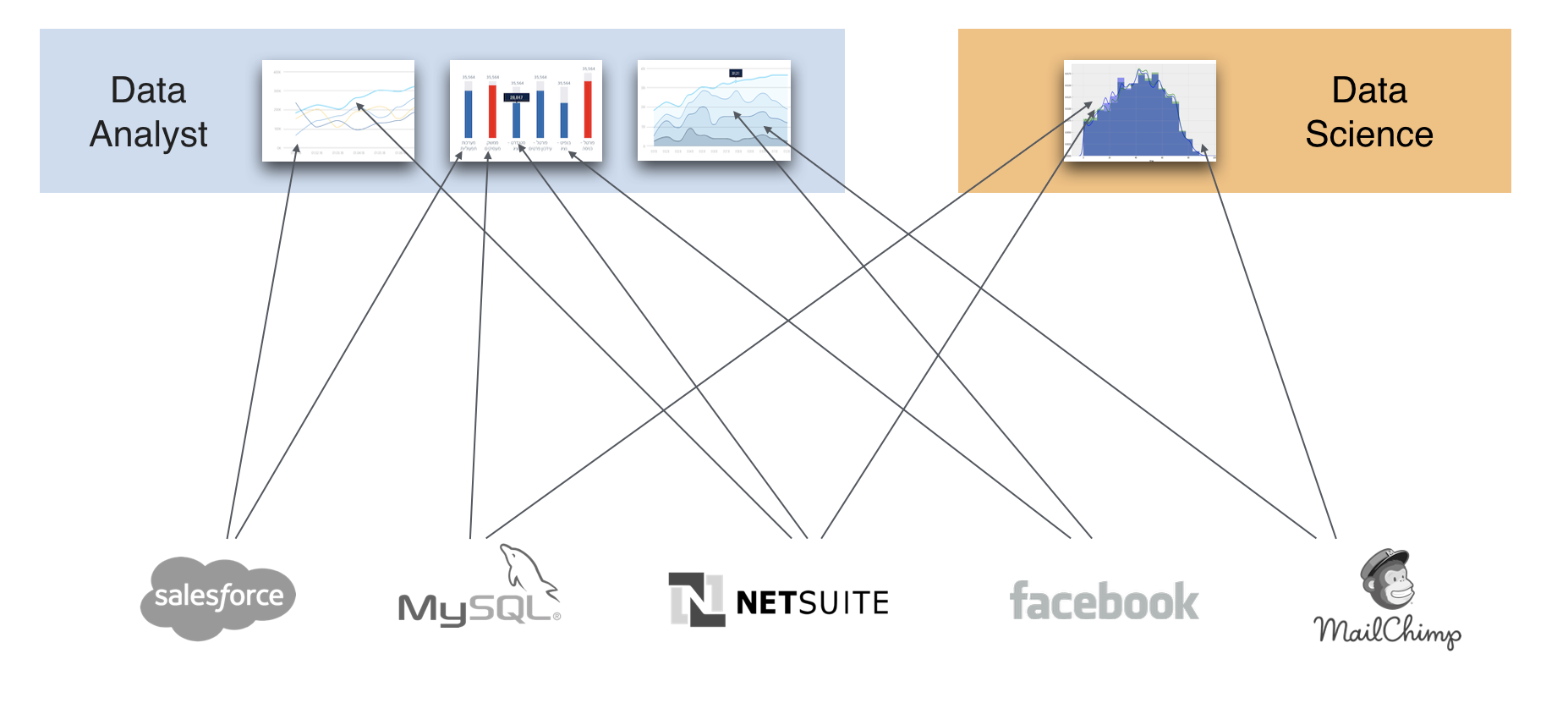
ארגון עם DE
להבדיל, בארגון עם תשתית מרכזית יש סנכרון נתונים זהה לכלל הארגון, שפה אחידה, נתונים זהים, תהליכי בקרה על הנתונים, חיבוריות לממשקים נוספים בארגון וכו׳
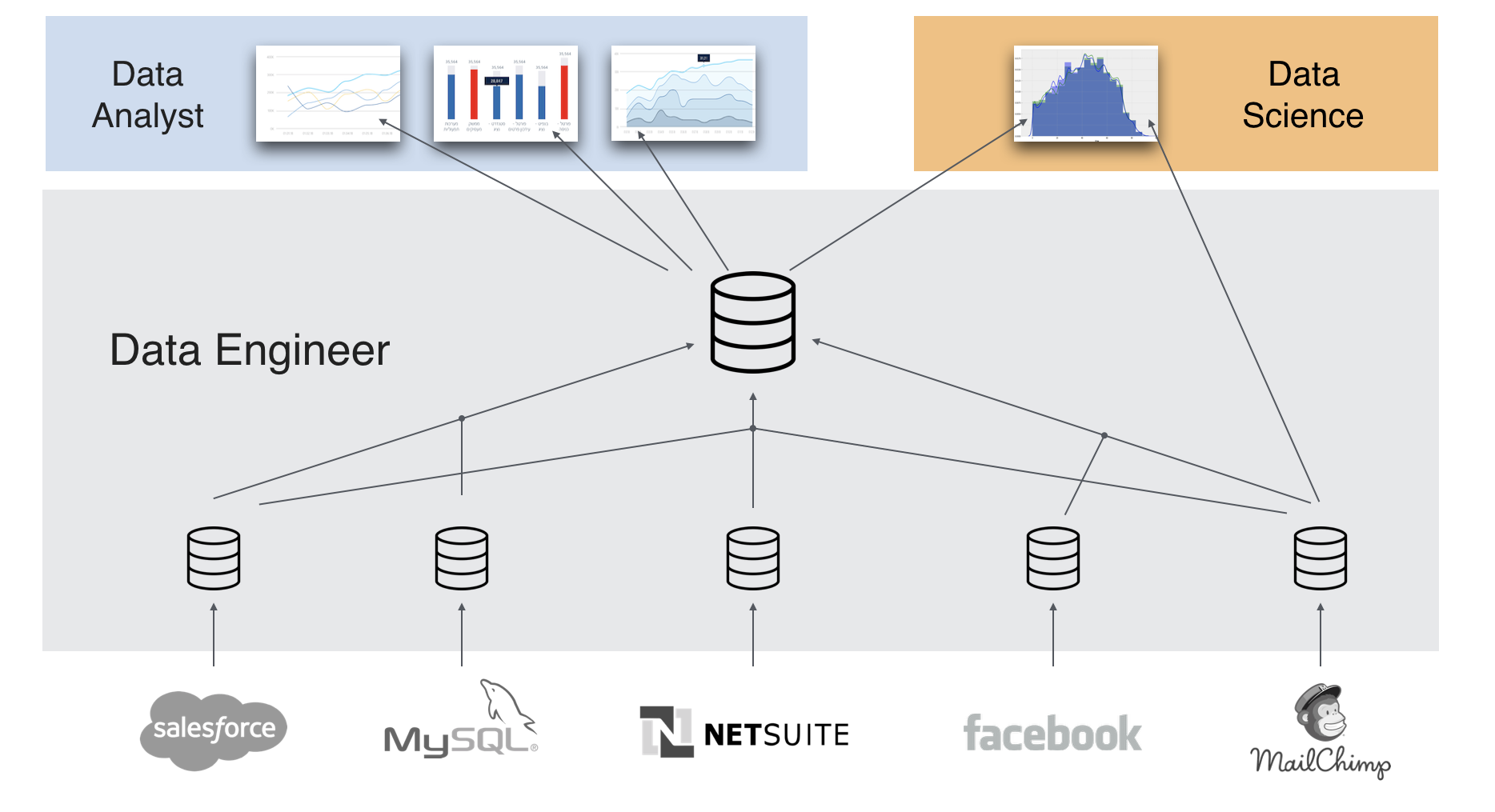
בחזרה לפוסט הקורונה
נחזור למקרה שלנו, מה היה תפקידו של ה data engineer הרבה לפני שהאנליסט התחיל לתחקר את המידע היה:
- הבאת נתונים ממקורות אמינים אוטומטית.
- הרצת עיבוד וטיוב המידע באופן שוטף שיהיה זמין ברמת התשתית ולא ברמת הדוחות בלבד
- חישוב מדדים כמו נירמול תאריכים, נרמול לגודל אוכלוסיה, מציאת 25 המדינות המוסילות, שוב שיהיה זמין לכולם ברמת התשתית.
- שילוב מידע נוסף כמו רשימת מדינות ה OECD ושילוב שלהם ברמת מידול הנתונים.
- הגדרת תלויות בין היישויות השונות
- בדיקת cycle של ריצה לוודא שהנתונים לא נדרסים, לא מכפילים את עצמם וכו'
- תזמון שוטף בכלי אינטגרציה
מול מי עובד ה-Data engineer
חשוב להדגיש שה DE הוא תפקיד טכולוגי. מורכב יותר או פחות, תלוי במקורות המידע ובמורכבות הנתונים.
אך בסופו של דבר צריך לחבר אותו לביזנס. בסוף הנתונים צריכים לענות שאלות עיסקיות. וכאן נכנס מידול הנתונים, מה שהופך את האתגר מתפקיד R&D טכני לתפקיד של Data modeler. מידול הנתונים בצורה נכונה זהו השלב בוא יש את היתרון למהנדס מערכות מידע להבדיל ממתכנת או מהנדס תוכנה. ניתוח הדרישות העיסקיות והמומחיות לתרגם את מבנה נתוני המקור (כפי שהם מגיעים המערכות) למבנה נתונים שידע לענות על כל שאלה עסקית ב- Self service, יודע לעשות מהנדס מערכות המידע, לרוב בתפקיד מנתח המערכות.
כאן בדיוק המקום לשלב את המומחים שהקימו כבר עשרות מערכות כאלו, שידעו לשאול את המשתמשים את השאלות הנכונות, ידעו לבנות תשתית סקיילבילית שתלווה את הארגון לפחות עשור קדימה אם לא יותר. זה בדיוק התהליך וההכשרה שהעברנו את חברות הסטארט-אפ המובילות והמצויינות ביותר בארץ.
לאחר שבניתם את התשתית הנכונה, זה הזמן להביא את החוקרים והמשתמשים השונים.
הכלים של ה-Data Engineer
הכלים איתם עובד ה-DE הם כלי אינטגרציה (ETL\ELT) ואחסון (בסיס נתונים). השוק מוצף במגוון כלים שמתאימים למגוון רחב של מקרים. ארגון לרוב לא יכול להספיק לבחון ולהכיר את כולם כדי לעשות בחירה מושכלת. זהו לרוב החלק בו הנסיון הרב שלנו תורם לחברות.
במרוצת השנים עבדנו עם כל טכנולוגיה אפשרית. עוד מימי MSSQL ו- OLAP, דרך Hadoop ו- Sqoop, פייטון, pandas, ספארק, Airflow ועוד הרבה. כל פרויקט שלנו מתחיל בבחירת הטכנולוגיות המתאימות ביותר ללקוח ומכאן גם ההיכרות עם כל הטכנולוגיות. תהליך הבחירה כולל בדר״כ כלי פרונט, ETL\ELT ובסיס נתונים. הבחירה יכולה להיות שונה ומגוונת לכל לקוח לפי הענן עליה הוא רץ, מקורות הנתונים ונפחים, אבטחת מידע, הדרישות של ה-product במידה וזה פתרון embedded ועוד. יש לנו מספר כלים שאנחנו עובדים איתם בשיתוף פעולה אבל אנחנו קודם כל ארגון טכנולוגי ומחוייבים רק לצד המקצועי ולהצלחת הפרויקט.
ה-Default שלנו
לאחר כל תהליכי הבחינה והבחירה האלו התגבשנו על סט כלים שעובד לנו הכי טוב. אנחנו קוראים לסטאק הזה RST. שזה קיצור של ריברי, סנופלייק וטאבלו.
Rivery - מוצר ELT מנוהל בענן. יודע למשוך מעשרות מקורות נתונים כמו Salesforce, Netsuit, Facebook ועוד המון. חברת ריברי היא Spinoff שיצא מויז׳ן בי איי ולעשה אורז בתוכו את כל המתודולגיות וה-best practices בתחום בדאטה. החברה יצאה לדרך עצמאית ועושה חייל במגרש הבינלאומי. המוצר נותן מענה מצויין ל-Data Integration בחיבוריות למקורות השונים ול-Data Transformation לאחר הטעינה.
Snowflake - אני מקווה שכבר לא צריך להציג לכם את החברה המשוגעת הזן. בסיס נתונים שהתאהבנו בו מהפרויקט הראשון והפך להיות ה-go-to שלנו מאז.
Tableau - כלי הויזואליזציה המוביל בעולם.
אבל כפי שציינו ישנם מקרים בהם פתרונות אחרים יתאימו לדרישות. העקרונות שלנו בגדול הם קודם כל התאמה טכנולוגית, פשטות בפתרון, תחזוקה קלה ופשוטה ומחיר.
ליצירת קשר
לקביעת פגישת היכרות מוזמנים לשלוח לנו מייל ל- info@vision.bi נשמח להפגש ולראות כיצד אנחנו יכולים לעזור לכם בתחום הדאטה.