לאחרונה נקראנו על ידי סנופלייק לנסות ״להציל״ לקוח שהשווה בין סנופלייק לאזו׳ר והיה בדרך לבחור באופציה השניה. סנופלייק לא היו מעורבים כל כך בבחינה, הלקוח בחן בעצמו בליווי מרחוק להבדיל מתהליך של מספר שבועות שנעשה על ידי צוות אז׳ור בליווי צמוד של מספר שעות ביום.
מבחינת הליווי והתמיכה במהלך ה-POC ללא ספק מיקרוסופט עשו עבודה מצויינת. מבחינת הטכנולוגיה? באנו לבדוק.
*דיסקליימר - אין כאן המלצה לטכנולוגיה אחת או אחרת, תהליך בחינה של פתרון צריך להיות מאד יסודי ומותאם לדרישות ול-use case שלכם. התהליך מתודולוגי, שדורש הכנה טובה של פרמטרים לבחינה, מדדים להצלחה ולבסוף בחירה. אתם יודעים איך הוא מתחיל אבל לא יודעים איך הוא יסתיים, אם עשיתם בחינה טובה ומעמיקה תגלו דברים שלא ידעתם לפני התהליך.
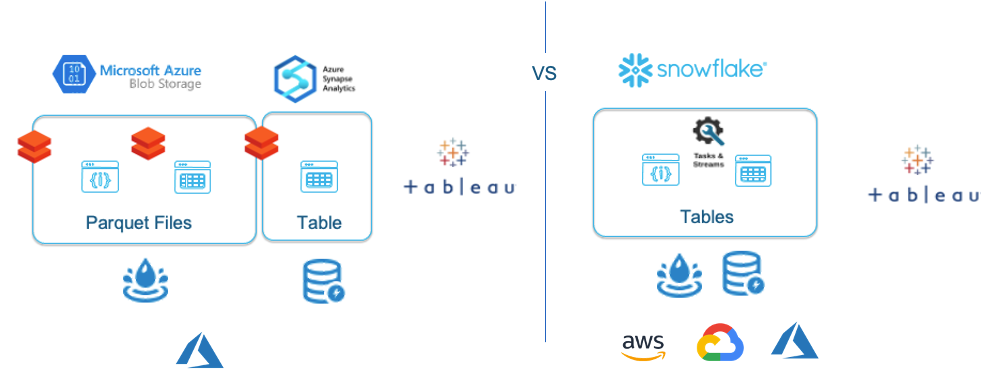
דרך הפתרון שנבחרה למימוש בסביבת אז׳ור היתה עיבוד נתונים ב-״דאטה לייק״ באמצעות Databricks. וטעינת המידע המעובד לסינאפס (ADW). דרך מקובלת וסטנדרטית באז׳ור, שכן ה-ADW אינו פתרון המתאים לטעינת Raw Data.
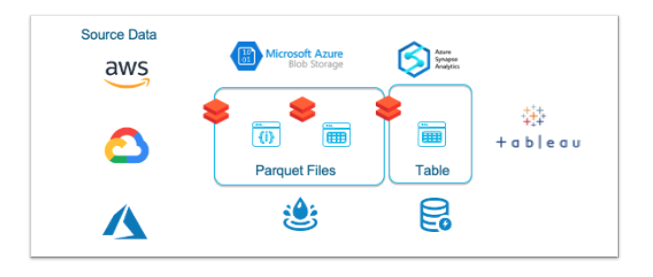
במהלך ה-POC על אז׳ור בוצע מימוש מלא של הפתרון הנ״ל כולל טעינת נתונים ל-ADW ותחקור מידע בנפחים גדולים 4.7 מיליארד רשומות בטאבלו מעל ADW.
תנאי פתיחה - השוואת ביצועים בטאבלו לייב
התנאי מבחינת הלקוח לבחינה חוזרת של סנופלייק היה להבין מדוע שאילתות שרצות ב-2-3 שניות על סינאפס לוקחות 2.5 דקות(!) על סנופלייק.
מבחינה ראשונית כמובן שהפערים נראו מאד גדולים והצוות מראש אמר שכנראה נובעים מכך שבסנופלייק הטאבלו מתבסס על View להבדיל מ-ADW שמדובר בטבלה.
אכן בחנו את הביצועים בטאבלו והיה נראה שהשאילתות מאד איטיות. בחינה קצרה של ה-Execution Plan הראה שב-View יש לוגיקה ואכן נדרש להשוות טבלה מול טבלה. כמו כן הנתונים בטבלה לא היו מסודרים באופן טבעי לפי סדר כניסת הרשומות, טעות נפוצה ב-POCs כאשר טוענים את כל הנתונים בטעינה אחת חד פעמית. לכן הוספנו Cluster Key.
לאחר שני השינויים המהירים הללו זמני הריצה בסנופלייק על WH בגודל Large הגיעו ל-3-5 שניות!
מדוע סינאפס מהיר יותר?
ללא ספק שיפור משמעותי לעומת נקודת הפתיחה אך עדיין סינאפס לוקח 2 שניות! חייב להודות שזה בהתחלה היה מאד מפתיע ומרשים. אך מהיכרות שלנו עם סנופלייק, בדרך כלל הביצועים טובים יותר מ-ADW - לכן ביקשנו לבדוק: בדקנו את גודל ה-ADW שהיה בשימוש וביקשנו לבדוק את הנתונים, כלומר האם הדוחות רצים על נתונים זהים?
להפתעתנו גילינו שני נתונים שמשנים הכל. ראשית ה-ADW רץ על שרת DW3000! שירות שעולה $45 לשעה. לא ברור מתי השתנה אבל מן הסתם לא רלוונטי לבחון שרת שעולה 32 אלף דולר לחודש. בסנופלייק לעומת זו נבחר שירות Large שעולה $24 לשעה. מיותר לציין שבסנופלייק משלמים רק על זמן שימוש, על כן מדובר בעלות של 6-8 שעות ביום, רק בימי עבודה, כלומר הערכה גסה $3,600 דולר לחודש לעומת 32 אלף... לא בדיוק השוואה רלוונטית.
*יצויין כי ניתן להוריד את ADW באופן יזום כדי לא לשלם על כל החודש אך זוהי פעולת תחזוקה שלא בהכרח נעשית בפועל עם חסרונות רבים.
לאחר שהורדנו את ה-ADW ל- DW2000, בעלות של $30 לשעה, הגענו לביצועים דומים של 3-5 שניות.
אבל הבדיקה לא הסתיימה בזה, התברר בבדיקת הנתונים שב-ADW יש רק 2.8 מיליארד רשומות, ולא 4.4 כמו בסנופלייק. מה שהכביד פי שניים על השאילתות בסנופלייק.

לסיכום סנופלייק הציג ביצועים דומים למרות שהיו פי 2 רשומות וב-20% פחות מבחינת עלות לשעה - תזכורת בסנופלייק משלמים על דקות שימוש.
מתקדמים לשלב הבא
אחרי שסנופלייק עמד בהצלחה בשלב הביצועים ואף ניצח בכל פרמטר להשוואה, הלקוח אישר להתקדם לשלב הבא, בחינת תהליכי שינוע ועיבוד הנתונים.
כאמור בסינאפס הפתרון מורכב מתהליכי עיבוד בדאטה לייק באמצעות Databricks, ועמדו לרשותנו כל הלוגיקות שבוצעו ב-Spark SQL, כך שהבחינה היתה מאד קלה להשוואה.
טעינת נתונים מ-API וקבצים המאוחסנים ב-Google BQ
במהלך המימוש ב-POC ב-Azure בוצעו טעינות באמצעות Databricks ל-Azure blog storage, שם הם עברו עיבודים כגון Join, פתיחת מערכים מתוך Json-ים והפיכת ה-Json (מובנים למחצה) למבנה טבלאי שיתאים לדוחות טאבלו. לאחר שהנתונים היו מוכנים הם עברו העתקה ל-ADW, גם כן באמצעות Databricks. על פניו פתרון סטנדרטי של מימוש Data Lake ומעליו בסיס נתונים אנליטי במקרה הזה ADW.
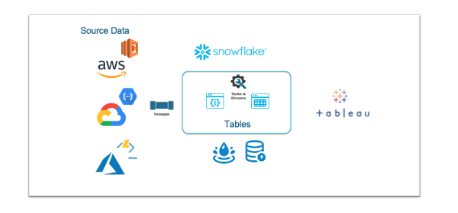
בסנופלייק לעומת זאת הרבה מזה לא נדרש מכיוון שאין חשש לטעון נתוני Raw Data וכן, לסנופלייק יכולות מעולות להתמודדות עם Json-ים וכל סוגי המידע המובנים למחצה (פרקט, אברו וכו׳). אפילו מידע המגיע מ-Stream, עובר אינדוקס ל-Micro partitions אוטומטית וזמין מיידית לתחקור ועיבוד. בנוסף, בסיום העיבוד המידע זמין מיידית בטאבלו, שכן אין צורך להעתיק לפתרון נוסף (בסיס נתונים אנליטי).
דרך המימוש בסנופלייק היא לממש Data Lake ו-Dwh באותה סביבה. זה כמובן נותן יתרון משמעותי למשתמשים שימצאו את כל המידע במקום אחד ולא ידרשו לפנות לאזורים שונים כדי לצרוך מידע ויתרונות נוספים כגון ניהול הרשאות מרכזי ו-Complience ניהול איכות המידע ובקרות או במילה אחת פשטות:
חזרה ל-POC ...
א - טעינת נתונים לסנופלייק
מקורות הנתונים היו API שמחזיר Json וכאמור נתונים מ-BQ. לצורך ההדגמה הצגנו מספר יכולות - ראשית טעינת API באמצעות פייתון (ללא שימוש באחסון מקומי) אותו ניתן להריץ מכל שירות מנוהל - AWS Lambda, Cloud Functions וכו׳ (בסנופלייק כיום לא ניתן להריץ פייתון ואכן זהו החלק בפתרון שדורש שימוש בכלי ניהול צד שלישי - זו גם ההמלצה). בהמשך הצגנו יכולת טעינת נתונים מ-API באמצעות Rivery Action, שירות של ריברי המאפשר למשוך נתונים מכל API ישירות לתוך טבלה בסנופלייק, כולל Merge לפי מפתח.
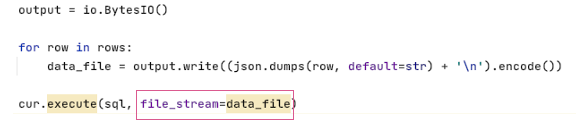
בהמשך הצגנו כיצד ניתן אפילו לטעון לסנופלייק ישירות מתוך Bucket של גוגל ( במקרה המדובר סנופלייק רץ על AWS - אך חשוב לזכור שסנופלייק תומך בכל 3 העננים). מה שמאד מפשט את הפתרון לאיטגרציה בין עננים.

עד כה הכל עבר חלק כצפוי, טעינת נתונים לסנופלייק יכולה להעשות בכל פתרון שהלקוח יבחר, אין כל מגבלה.
ב- עיבוד נתונים ב-SQL
לאחר שהנתונים הגיעו לסנופלייק ניתן לנהל את הכל באמצעות SQL פשוט. את ה-SQL ניתן להריץ בכל כלי ELT או בפרוצדורות בתוך סנופלייק (פחות מומלץ). במקרה הנ״ל הצגנו כיצד ניתן להריץ הכל באמצעות Rivery, מה שיאפשר לראות במקום אחד את כל ה-Pipeline, החל ממשיכת נתונים מ-API עד לטעינת הנתונים ל-DWH. אך כאמור על הלקוח לבחור את הפתרון המתאים לו ל-ELT.
כל הלוגיקות שבוצעו ב-Data bricks מומשו בקלות על ידי SQL בסנופלייק, כולל פתיחת מערכים, שיטוח Json-ים ועוד. ה-SQL היה מאד קל ופשוט הסבה לסנופלייק.
כך שעל פניו ברכיב ה-Data Pipeline הפתרונות דומים, למעט היתרון (המשמעותי ביותר) שיש לסנופלייק, והוא פתרון אחיד לכל צרכי הדאטה של הארגון. לסיכום השוואה בין הפתרונות:
- סנופלייק אינו דורש להעתיק את המידע לצורך תחקור בטאבלו (כפי שנדרש להעתיק ל-ADW)
- בסנופלייק כל המידע - ה-DL וה-DWH יושב על אותו פתרון
- העיבוד והתחקור נעשים ב-SQL אחיד. ולא שילוב של Spark Sql עם פייתון מצד אחד ו-MS Sql בבסיס נתונים האנליטי.
אז מה בכל זאת ההבדלים?
כל הפערים הנ״ל מאד חשובים ברמת ארכיטקטורה ועיצוב הפתרון, אבל איך זה בא לידי ביטוי בעבודה היומיומית? לצורך זה רצינו לבדוק את זמן הריצה מקצה לקצה של המידע, מהרגע שהוא מגיע מ-API עד לזה שהוא ניתן לתחקור בטאבלו.
הדרישה עסקית כיום היא פעם בחצי שעה עד שעה ובהמשך תעלה לעדכון של כל 2 דקות, שכן מגיעים מה-API נתונים בזמן אמת החשובים לצורך תפעול.
ואכן כשבוחנים תהליך Pipeline מקצה לקצה הפערים בארכיטקטורת הדאטה מתגלים. פתרון אחד בו המידע עובר בדאטה לייק ורק אז מגיע ל-Dwh, לעומת פתרון שני בו כל המידע מעובד ומתוחקר באותה סביבה. והפערים גדולים מאד. מצד אחד העתקת מידע ל-ABS, עיבוד והעתקה ל-ADW. הלקוח העיד שמדובר בתהליך של 12-13 דקות(!) לא כולל עליית הקלאסטר של Databricks. בסנופלייק לעומת זאת תהליך הטעינה והעיבוד ארכו 39 שניות (!) וכמובן אין צורך בהעתקת המידע לבסיס נתונים אחר.

הדרישה העסקית לא תשתנה כמובן, הלקוח העסקי צריך את המידע כל 2 דקות בטאבלו, זה המקום בו יתחילו הקיצורי דרך כדי לתמוךבצורך העיסקי, אולי לדלג על ה-DL? יצור חוסר אחידות ארגוני ובלאגן. אולי לכתוב במקביל לשניהם? בעיית איכות נתונים וכפילויות וכן הלאה. לכל דבר ניתן למצוא פתרון, השאלה למה מראש להיכנס לפתרון שיוצר בעיה?
נוסיף עוד כמה פערים שעולים בין הפתרונות, כגון שימוש בריבוי טכנולוגיות, דורש skills גדולים יותר ועקומת לימוד, יצירת איי מידע, משילות של מידע המבוזר בטכנולוגיות שונות ועוד.
ולא התחלנו לדבר על כל הקילר פיצ׳רז של סנופלייק. Time travel, Clone, Data Sharing, Anonymized Views ועוד...
לסיכום זו טבלת ההשוואה שיצאה לנו ב-Data pipeline

עלויות
אנחנו הישראלים אוהבים לשאול את זה בתור השאלה הראשונה :-) אבל המתודולוגיה צריכה להיות ראשית איזה פתרון הכי טוב ונכון לארגון. פתרון פחות טוב יעלה לארגון הרבה יותר מכל השוואה שנעשה לפי עלות של שרת לשעה. חצי משרה של תחזוקה גבוהה יותר לאחד הצדדים למשל תשנה כל טבלה להשוואת עלויות. לכן את סעיף העלויות שומרים לסוף.
אז לא הוספנו כאן את הפרק של השוואת העלויות, אבל גם בסעיף העלויות סנופלייק יצא משמעותית יותר אטרקטיבי.
למשל כאשר הרצנו את התהליך במשך כמה ימים עם טעינה של כל 5 דקות, הגענו לזמן שימוש של 25% על WH הקטן ביותר (X-Small) - כלומר 6 קרדיטים ליום.

לסיכום
יש כיום אין סוף טכנולוגיות ודרכים לפתור את אתגרי הדאטה בארגון. החכמה היא למצוא את הפתרון הנכון והפשוט ביותר שישרת את האתגרים שהצבתם. כל אתגר ניתן לפתור בכמה דרכים, לראיה בסיום ה-POC הראשון (אז׳ור), מבחינת הארגון נמצא פתרון שנותן מענה לכל הצרכים, אבל השאלה היא האם מצאתם את הפתרון הנכון והמתאים ביותר שיצמח איתכם לשנים הבאות. במקרה הזה לפחות לאחר בחינת שני הפתרונות, סנופלייק ניצח בכל הפרמטרים שנבחנו. ברמת תשתית הדאטה, ברמת קלות המימוש, היכולת לגדול ואף ברמת העלויות.
שאלה נוספת שאתם צריכים לשאול את עצמכם, היא מדוע צוות הארכיטקטים של אז׳ור, שעצב את הפתרון מצא לנכון להמליץ על Databricks ולא על סנופלייק למשל (שגם רץ על אז׳ור)? Databricks טכנולוגיה מצויינת וראויה, אבל במקרה הזה נראה שהיא קצת Overkill לאתגרים הנוכחיים והעתידיים של הלקוח. חומר למחשבה.
*דיסקליימר 2 - כשותף בכיר של סנופלייק, באנו לתהליך על מנת לבחון את היתרונות בסנופלייק על פני הפתרון שעוצב על ידי מיקרוסופט. לכן הכתוב מצד אחד חד צדדי ומצד שני מדוייק ונאמן לעובדות. מבחינת היתרונות בפתרון על אז׳ור כן ניתן לציין לטובה את Databricks כמוצר רובסטי המאפשר להריץ תהליכי פייתון וספארק על סביבה מנוהלת ואת היכולת ב-Databricks לזהות אוטומטית סכימה באובייקט Json (בסנופלייק נדרש לכתוב איזה רכיב רוצים לחלץ, ב-Databricks הוא חילץ אוטומטית את כל הרכיבים. שני הפתרונות אינם מאבדים מידע בתהליך וזה העיקרון החשוב עליו צריך לשמור. לגבי ההבדל בין פריסה של כל העמודות או השארת המידע בעמודת Json אחת, זו כבר העדפה אישית). אך בשורה התחתונה האם יש צורך ב-Databricks המביא איתו את החסרונות של Data Lake בנפרד מה-Dwh ? התשובה לדעתינו היא לא. ל-Databricks יש בהחלט מקום בפתרון בהרצת תהליכי ה-DS וה-ML. האם הוא צריך להיות צוואר בקבוק ב-Data pipeline ? יתכן ויש מקרים שזה יכול להתאים, מניסיוננו ב-95% מהמקרים אין בו צורך.
רוצים לשמוע עוד על ההשוואה בין הפתרונות מוזמנים לפנות אלינו.