
בתחילת נובמבר databricks פרסמו פוסט בו הם מכריזים שהם שברו את כל השיאים במבחן הבנצ׳מרק של TPC-DS, הסטנדרט לביצועים בתחום ה-DWH. והם עשו זאת עם databricks SQL, המוצר החדש שהושק לפני כשנה. ההכרזה כמובן ראויה ובהחלט שמה אלטרנטיבה שיש להתייחס אליה, אך בחירה קצת פחות ראויה וקצת מוזרה היא הבחירה להשוות את תוצאות הריצה דווקא לסנופלייק. סנופלייק לא החזיקה בשיא הקודם ומעולם לא השוותה את עצמה למתחרים אחרים, אז למה databricks בחרו דווקא בסנופלייק? ברור ולא ברור. בכל אופן databricks לא רק שהם בחרו לפרסם את התוצאות בביצועים הם גם הגדילו לעשות והשוו את הפערים בעלויות ($).
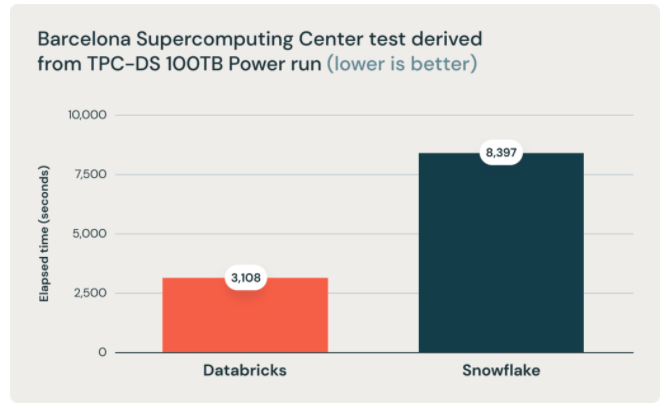
כאמור פורסמו גם ההבדלים בעלויות, ולא רק שפורסמו בפוסט, הם גם מופיעים כרגע בעמוד הבית של databricks SQL:
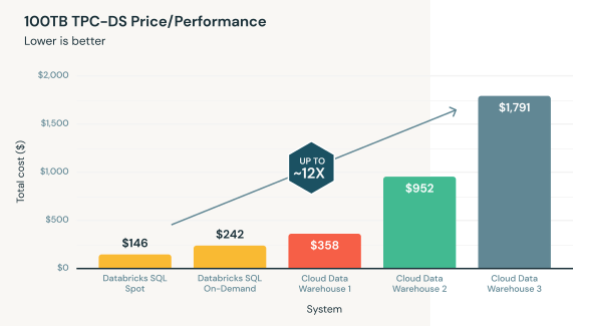
סנופלייק מגיבה
לקח לסנופלייק כ-10 ימים והם (לא אחר מהמייסדים עצמם) הגיבו עם פוסט משלהם שעוקץ את המתחרה החדשה ואומר - תעשו איזה בדיקות שאתם רוצים רק תעשו את זה עם Integrity. סנופלייק מצידה פרסמה הנחיות כיצד כל אחד יכול ליצור חשבון חינם (עם קרדיט של 400$) ולהריץ את הבחינה בעצמו. דבר שאינו אפשרי כמובן אם העלויות הן אכן $1,791 כמו ש-databricks טוענים.
תגובה על תגובה
יומיים לאחר מכן, databricks הגיבו לעקיצה בטענות שונות המסבירות מדוע הבחינה שלהם כשרה לחלוטין וגם כן ממליצים להריץ את התהליך המלא כפי שהם שלחו לאגודת TPC.
ההסברים של databricks
מבחינת ביצועים databricks טוענים שאם מריצים את התהליך המלא ולא על הדמו דאטה הקיים בכל חשבון סנופלייק התוצאות שונות.
ומדוע הפער הגדול כל כך בעלויות ובמה ש-databricks בחרו לפרסם באתר הבית שלהם, כאן התשובה קצת יותר מהוססת:

בתרגום חופשי - לא נכון להשוות את הגרסה הזולה ביותר של סנופלייק ומזכירים של-databricks יש עוד שירותים מחוץ ל-databricks SQL שמאפשרים להשתמש בשרתי spot שיכולים להוריד עלויות.
ניתחנו את הפוסטים והטענות
ראשית זה לא סוד שאנחנו חסידים של טכנולוגיית סנופלייק, אבל לא להתבלבל, אנחנו קודם כל חסידים של טכנולוגיה, כלומר טכנולוגיה טובה. כאשר בחרנו בסנופלייק להיות ה-go-to שלנו זה היה על חשבון בסיסי נתונים וטכנולוגיות data lake שלא התקרבו בעבר ולא מתקרבים עד היום למה שיש לסנופלייק להציע. עם זאת התפקיד המקצועי שלנו היה ותמיד יהיה לבחון טכנולוגיות חדשות, להישאר מעודכנים ולהגיש ללקוחות שלנו את הטכנולוגיה הראויה ביותר לצרכים שלהם. מה שנכון לכל איש מקצוע בתחום.
אז ישבנו והעמקנו בטענות בצורה המקצועית ביותר שאנחנו יודעים ולהלן המסקנות. נציין שאנחנו לא מומחים ב- databricks SQL, זהו מוצר חדש יחסית, אך יצרנו חשבון והתעמקנו ביכולות.
הפערים בביצועים
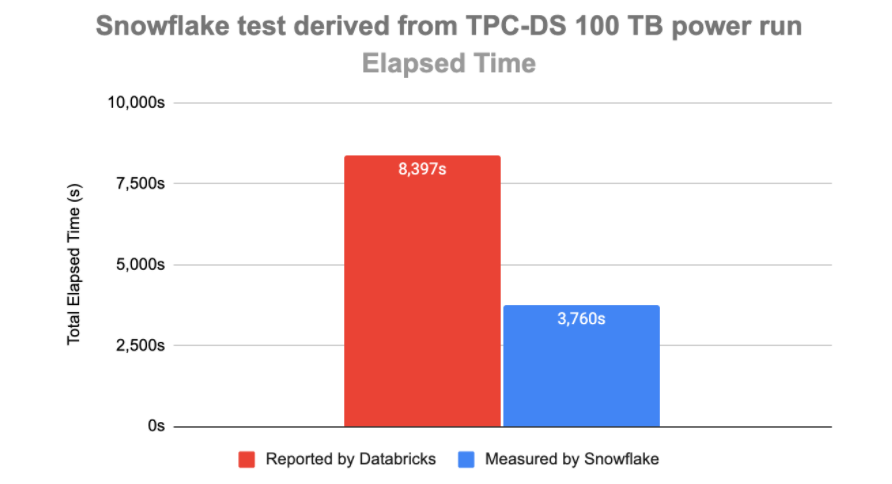
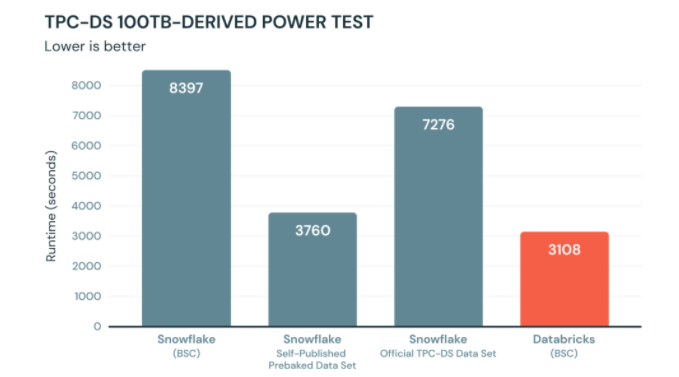
נתחיל בפערים הגדולים בביצועים. שתי החברות טוענות למספרים שונים לחלוטין, מי מהן צודקת? ובכן סנופלייק הציעו להריץ את המבחן באופן עצמאי - זה בדיוק מה שעשינו. פתחנו חשבון חדש, טענו את הסקריפט והרצנו. התוצאות היו קרובות מאד (4,200 שניות) למה שסנופלייק פרסמו וקטן בחצי ממה ש-databricks פרסמו בפוסט. אז סנופלייק קצת יותר מדייקים.
databricks מצידם אומרים שאלו לא התוצאות אם מריצים את הסקריפט המלא לפי TPC ושסנופלייק סידרו את המידע בבסיס נתונים ב-snow share. אחלה, אבל אנחנו יודעים שבסנופלייק אין אינדקסים, אין hint-ים ואין כמעט כלום שניתן לעשות על הדאטה למעט cluster על טבלה. אז אם סנופלייק יצרו קלסטר של 5 טבלאות שקיצר בחצי את זמן הריצה, למה לקחת את הזמן ריצה הארוך? סביר שזה מה שכל לקוח יעשה, פעולה שלוקחת בדיוק חמש דקות ללא כך צורך בתחזוקה עתידית.
מה עם ה- Data Sharing? אי אפשר להתעלם מזה שלא היה כל צורך לטעון לסנופלייק את הדאטה של TPC כי הוא פשוט קיים ב-Market place. אחת היכולות המשוגעות שיש לסנופלייק להציע, להוות cloud data של כל הארגונים והמידע שתצטרכו פשוט יהיה שם נגיש בלחיצת כפתור וכפי שרואים מהבחינת ביצועים הזו ממש, תקבלו ביצועים טובים ביותר על מידע שלא אתם שומרים/מנהלים ואתם אפילו לא משלמים על האחסון שלו.
ודבר אחרון, אסור לשכוח שהבחינה כולה, מדברת רק על שאילתות Select! הבנצ׳מרק כולו כולל 99 שאילתות SELECT על כ-5 טבלאות מקור. האם זו הדרך להשוות ביצועים של פלטפורמת דאטה? האם ניתן להסתמך רק על Select? הרי ברור שבפלטפורמת Data (לא משנה אם Dwh או Data Lake) לפחות חצי מהעבודה אם לא יותר היא עיבוד של המידע, תהליכי Merge, Upsert וכד׳. אז בוודאי שלא ניתן לקחת את הבחינה הזו כמדד מרכזי מבלי לבחון עוד סוגי שאילתות.
לסיכום הביצועים
ניתן לומר ש-databricks הציגו תוצאות מרשימות בבחינת הביצועים של TPC. נדרש כמובן לבחון איך מנוע ה-SQL החדש של Databricks SQL מתנהג גם בביצועים של תהליכים עיבוד כדי לקבל את התמונה המלאה אך חבל שהם מנסים לעשות זאת על חשבון סנופלייק תוך כדי הם מלכלכים ידיהם כי הביצועים של סנופלייק לא נופלים והקלות בה ניתן לבחון את סנופלייק רק מדגישה יתרונות רבים אחרים שיש לסנופלייק להציע. או כמו שאמר לי קולגה יקר, השוואת ביצועים של בנצ׳מרק זה כל כך 2010.
הפערים בעלויות!
אוה, כאן אפשר להתחיל לעוף מבחינת אי הדיוקים הרבים וכאן זה באמת הולך להיות מעניין.
״סנופלייק? זה יקר!״
מזה שלוש שנים, אנחנו עוזרים ללקוחות לנהל את חשבונות הסנופלייק שלהם, אפילו כתבנו מוצר שלם Arctica.AI שבאמצעותו אנחנו משקפים את העלויות ברזולוציה נמוכה כל כך המציגות ללקוח בדיוק על מה הוא משלם ומאפשרת לקבל החלטות האם זה משתלם או האם על ידי שינויים קלים כמו שינוי תדירות עדכון, משנים את העלויות.
לכן אנחנו תופסים את הראש בכל פעם שאנחנו שומעים את האמירה הכללית הזו ש״סנופלייק יקר״.
ואכן, אין ספק שמי שרואה את התמונה הזו, יכול לומר ממבט ראשון שסנופלייק זה יקר וחבל אפילו לבדוק את זה. לא רק שזה יקר, זה יקר פי 12!
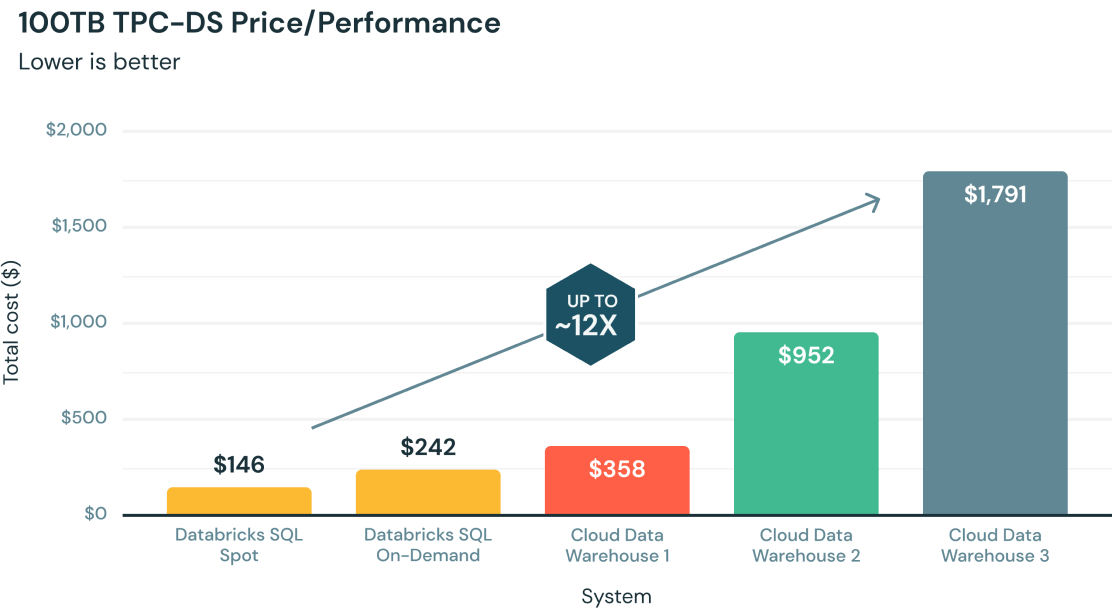
אז ניקח את המקרה הזה ממש, של חברה רצינית שטוענת שסנופלייק עולה $1,791 להרצת 99 שאילתות על פני $146 בלבד ב-databricks.
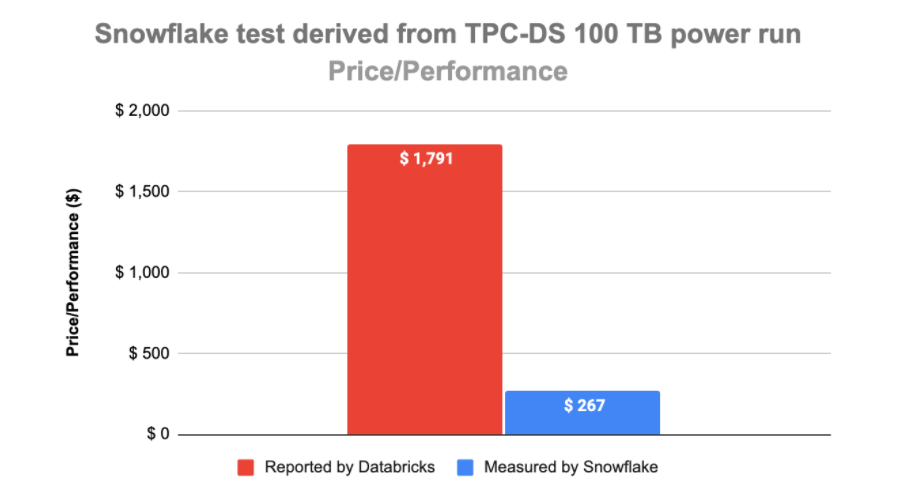
ראשית כאמור לא ברור מאיפה הגיע המספר של databricks, הם כתבו משהו על גרסאות אבל לא הבנו אז פשוט הרצנו את הבחינה בעצמנו - לקחנו את השאילתות של סנופלייק בחשבון חדש שיצרנו וקיבלנו את התוצאה הבאה:

סך הכל 161 קרדיטים, לפי גרסת סטנדרט של 2$ לקרדיט אנחנו מקבלים 322$ (נדבר על גרסאות בהמשך).
אז בבדיקה זו סנופלייק לא יקר פי 12, אם כבר הוא יקר פי 1.5. אבל גם זה יקר מאד, האם סנופלייק באמת יקר פי 1.5? כאן, כנראה שמי שלא עוסק בניתוח עלויות סנופלייק ברמה שוטפת יתקשה להסביר. כדי להבין את זה צריך להתעמק בהבדלים שיש ב-Compute של שתי הפלטפורמות:
Auto Resume
לשתי הטכנולוגיות יש Auto Resume אוטומטי, כלומר אתה לא משלם על ה-Compute כל עוד אתה לא משתמש וכאשר אתה משתמש השירות ״מתעורר״ לבד ומריץ את השאילתא, רק אז התשלום נחשב. אלא שכאן בדיוק הפער בין סנופלייק ל-databricks. ה-Compute בסנופלייק מתעורר מיידית מכיוון שכל השרתים מנוהלים בסנופלייק והם כבר ב״אוויר״. לעומת זאת ב-data bricks זמן ההתנעה של cluster הוא סביב ה-3 דקות. מה שאומר שב-Use case כזה של Select-ים בלבד, שלרוב מיועד לאנליסטים, אף אחד לא יתן לקלסטר ״לישון״ כדי להמנע מהקנס הזה של שלוש דקות ״התנעה״. בדיוק בגלל זה data bricks הכריזו על Instant start cluster אבל יכולת זו לא קיימת כרגע ולכן אולי היה מוקדם מידי לרוץ לספר שסנופלייק יותר יקר.
מה המשמעות מבחינת עלויות? סביר שב-databricks הקלסטר יהיה פעיל כל 9 שעות הפעילות היומיות, לעומת סנופלייק שיהיה פעיל רק כשרצות באמת שאילתות. במקרה שלנו השאילתות רצו נטו 70 דקות, תוסיפו 10% על מרווחים בסופי שאילתות, אפילו נעגל ל-90 דקות. ב-databricks סביר שתשלמו על 9 שעות * 60 דקות - 540 דקות. כלומר פי 6!
במקרה אחר בו אתם משתמשים בטאבלו למשל (שטוען אליו את הנתונים) ותגדירו אותו לרוץ כל שעה תשלמו בסנופלייק רק 24 דקות ״לשווא״ לעומת 240 דקות ב-databricks - פי 10! (לא כולל 3 דקות של Auto Resume)
Auto Suspend
לשתי הטכנולוגיות יש גם Auto Suspend, אבל גם כאן יש הבדל מהותי. הפער ב-Auto Suspend כרגע הוא דקה בסנופלייק לעומת 10 דקות ב-databricks.
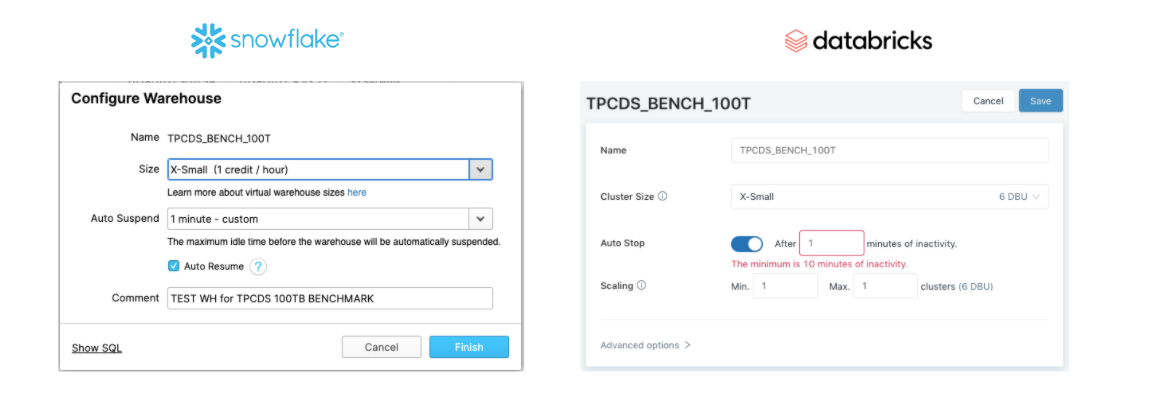
על פניו הבדל קטן, העיקר ששניהם יודעים ״לרדת״ לבד. ובכן, במקרה הזה זה באמת קשה להעריך את הפער בעלויות, אבל במקרה היה לנו לקוח שהריץ שאילתות בסנופלייק על Warehouse שהוגדר עם 10 דקות Auto suspend, וכשראינו שיש המון זמן ״מת״, כלומר זמן שהוא שילם על ה-WH אך הוא בפועל לא היה פעיל, ביקשנו שישנה לדקה. ההבדל היה דרמטי!
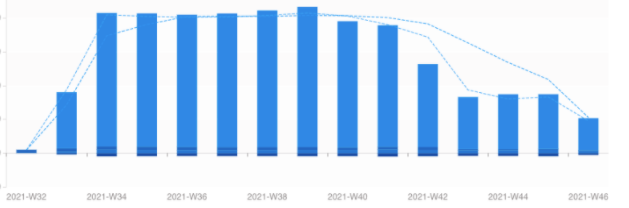
הבדל של פי 2 עלות יקרה יותר של databricks. גם כאן לסנופלייק יש יתרון משמעותי שהופך אותו להיות יותר זול.
הבדלי גרסאות
בפוסט התגובה של databricks הם כתבו שהעלויות הגבוהות בסנופלייק הן בין היתר בגלל הבדלי גרסאות וסנופלייק בתגובה שלהם התייחסו לעלויות של Standard להבדיל מ-databricks
At face value, this ignores the fact that they are comparing the price of their cheapest offering with that of our most expensive SQL offering. (Note that Snowflake’s “Business Critical” tier is 2x the cost of the cheapest tier.)
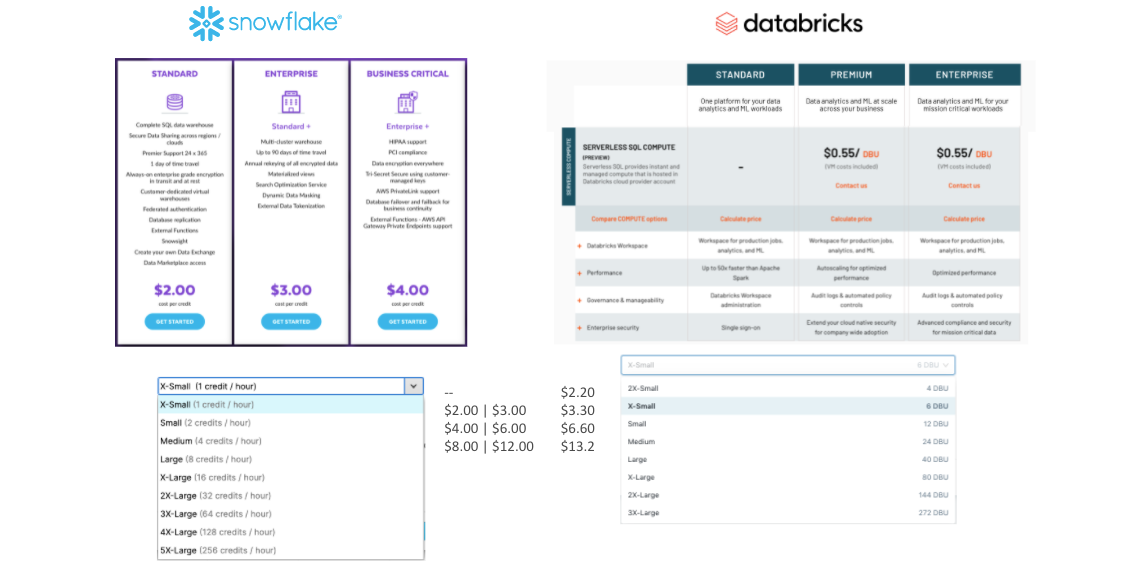
האמירה הזו יוצרת פער נוסף בהשוואה בין databricks לסנופלייק שכן כדי לענות על ההבדלים צריך להשוות בין הגרסאות השונות. ואם ניכנס להשוואה של פיצ׳רים בין המוצרים נראה ש databricks SQL הוא מוצר חדש יחסית עם פערים עצומים בינו לבין סנופלייק. יהיה קשה למנות את כולם, אבל הפערים הבולטים ביותר.
פיצ׳רים בסנופלייק שלא ראינו ב-databricks
- Data Sharing ו-Market Place - סנופלייק משקיעה המון משאבים ביצירת סביבת דאטה עשירה ללקוחות שתאפשר לייצר אינטגרציה בין מערכות ללא כל צורך בשינוע נתונים. לקוחות כבר היום משתמשים ב-Market place להעשיר את המידע הקיים ממאות datasets זמינים.
- Operate Globally - נכון ששני המוצרים רצים על Azure, AWS & GCP אך בסנופלייק ישנו UI אחד המאפשר לנהל הכל ממקום אחד, כולל sharing ורפליקציה בין Regions & Clouds. כמו גם רפליקציה של כל ה-meta data בין חשבונות. ניהול משתמשים הרשאות ועוד ממשק מרכזי.
- High Availability - בגרסת ה-Enterprise ישנו מנגנון רפליקציה מנוהל של נתונים המאפשר מעבר אוטומטי בין חשבון אחד לשני במקרה של disaster.
- ניהול מידע רגיש ו-PII - מנגנון Dynamic Data Masking ו- Row level security מובנה.
- ממשק SQL לביצוע כל הפעולות שניתן לעשות מה-UI. למשל יצירת Warehouse, שינוי הגודל (Scale-up) ועוד, הכל דרך SQL פשוט.
- Time travel - ניהול גרסאות של הדאטה - יתכן שקיים מימוש כלשהו ב-databricks אך לא זמין עדיין ב-UI.
- Zero copy clone - יכולת לשכפל בסיסי נתונים וטבלאות מבלי לשכפל את הדאטה עצמו.
- Account_Usage - עשרות טבלאות ניהול לניתור ואופטימיזציה של השימוש והעלויות. כולל ניהול גישה למידע. מי ניגש לאיזה אובייקט ומתי, תלויות בין אובייקטים (Lineage) ו-Anonymized Views המאפשר להסיר מידע רגיש אוטומטית למשתמשים שאינם מורשים.
- Information_Schema - בסיס נתונים עם כל ה-Meta data כל אובייקטים.
- תצוגה גרפית ומאד אינפורמטיבית של ה-Execution Plan של שאילתות, לצורך ניתוח ושיפור ביצועים.
נעצור ב-10, יש עוד הרבה... אך ממבט ראשון על ה-UI של databricks SQL אפשר לומר שהוא עדיין בתחילת הדרך וחסר הרבה מאד יכולות שקיימות מזמן בסנופלייק. אין ספק שהם יתווספו למוצר בהדרגה, אך גם סנופלייק לא בדיוק עומדים במקום.
לסיכום
אין ספק ששתי הטכנולוגיות יושבות על אותה משבצת של All Data for All Users. האחת באה מעולמות ה-Data Lake ונכנסת לעולמות ה-Dwh והשניה שעשתה את המעבר בכיוון ההפוך כבר לפני מספר שנים. יהיה מאד מעניין לעקוב אחר שתיהן ולראות את ההתקדמות ואיך יגיבו ספקי הענן שעדיין מספקים פתרונות שונים ל-Data Lake ו-Dwh. ניתן להניח שהאבחנה בין שני במושגים תעבור מן העולם בקרוב ונתחיל לדבר רק במונחי Data Platform, זה מה שאנחנו לפחות עושים בשנים האחרונות.
ולגבי הפוסטים והפרסומים האחרונים, להערכתנו databricks קצת הקדימו את ההכרזות שלהם ומוטב היה שיפרסמו את התוצאות הטובות על שאילתות Select מבלי להשוות את עצמם לטכנולוגיות אחרות, לא בביצועים ובטח לא בעלויות בצורה כל כך רשלנית.