
בארוע הפתיחה העביר פרנק סלוטמן, מנכ״ל החברה, את סיכום השנה בה יצאה סנופלייק להנפקה ואת החזון לאן החברה הולכת. הרצאות הכנס זמינות לצפיה ומומלץ לבקר באתר סנופלייק לצפות בחלקן. צריך להקשיב בעיקר לחזון החברה כדי להבין שיש כאן משהו הרבה יותר גדול מבסיס נתונים או מפלטפורמת דאטה. סנופלייק שואפת לחזון משמעותי של ענן דאטה גלובאלי, בה יצרני הדאטה וצרכני הדאטה חולקים את אותה סביבה עסקית וטכנית. הציטוט של סמנכל״ית דיסני, שהציגה כיצד סנופלייק עוזרת להם לנהל את כל הדאטה במקום מרכזי, אולי משקף את זה הכי טוב: ״אתם רוצים להגיע מהר תלכו לבד, אתם רוצים להגיע רחוק, תלכו יחד״ נשמע קצת קלישאתי אבל כשרואים חברות ענק כמו סיילספורס ו-100 ספקי דאטה נוספים, חולקים את אותו חזון ומצטרפים לדאטה marketplace של סנופלייק רק בחצי שנה האחרונה, אפשר להבין שיש כאן חזון של ממש שמתהווה.
בפוסט זה נסקור את הכרזות הטכנולוגיות. נזכיר שביוני האחרון היה הכנס הראשון של 2020 בו היו לא מעט הכרזות טכנולוגיות ובכנס זה הוסיפו עליהם עוד מספר השקות מרתקות.
אסטרטגיית המוצר בארבעה ערוצים מרכזיים
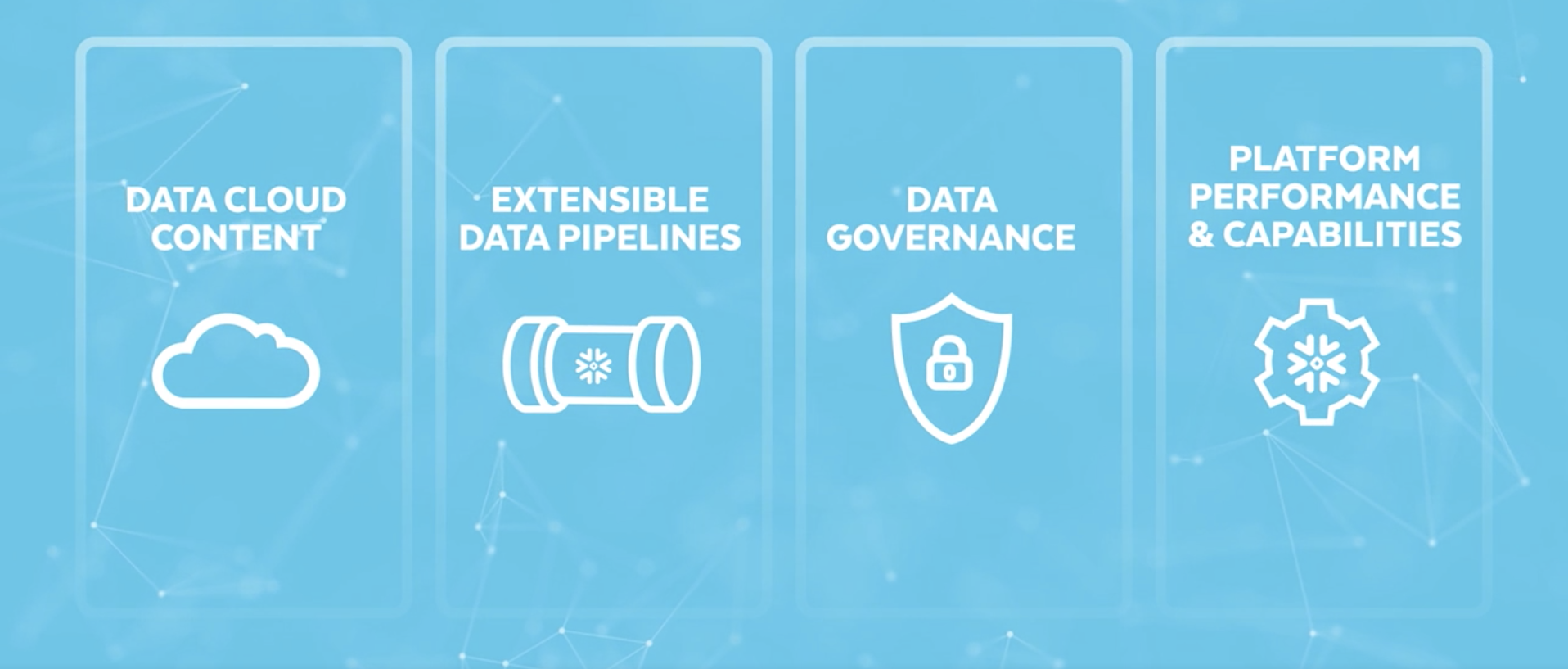
וכך גם נסקרו הנושאים החדשים.
תוכן - Data Cloud Content
במהלך השנה האחרונה הצטרפו ל-Data Marketplace מעל 100 ספקי דאטה גלובאליים. זהו כוח עצום המאפשר לחברות לצרוך מידע חיצוני שעד כה היה קשה להשיג ודרש לא מעט תהליכים טכניים, החל ממציאת מקורות נתונים רלוונטיים, דרך התקשרות עסקית עם אותם ספקים, יבוא הנתונים וטעינתם לסביבת המחקר ורק לאחר מכן להתחיל להשתמש בהם. ה-Data marketplace לעומת זאת מאפשר לחפש נתונים במאגר עצום, לייבא Datasets בלחיצת כפתור ולא לדאוג יותר לסנכרון, הדאטה מנוהל על ידי ספק המידע ומתעדכן בתדירות קבועה.
דמו - כיצד חברת insureco עושה שימוש ב-Marketplace
חברת insureco היא חברת ביטוח דמיונית. ובמהלך הדמו הציגו כיצד אנליסטים בחברה מצליבים מידע מה-Marketplace החיצוני למידע מ-Saleforce הזמין ב-Marketplace הפנים ארגוני(!) ולמידע תביעות הקיים בבסיס הנתונים. שילוב של 3 מקורות מידע ללא כל תהליך ETL או שינוע מידע. זהו למעשה החזון של ה-Cloud Data.
Extensible data pipelines
כמו בכל כנס בשלוש שנים האחרונות סנופלייק שמה דגש על הרחבת יכולות ה-SQL. זה התחיל בפונקציות ופרוצדורות Java script ובהמשך גם בשפת SQL, בכנס ביוני הושק לראשונה ה-External Functions המאפשרת לקרוא לפונקציות הנמצאות על ענן התשתית כמו AWS והיום סנופלייק מכריזה על Snowpark, ספריות עבור ה-Data Science לכתיבת פונקציות, מודלים ולוגיקות שלבסוף ירוצו על הפלטפורמה של סנופלייק.
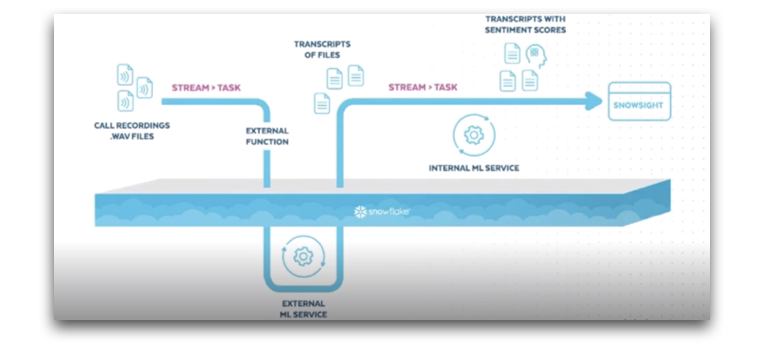
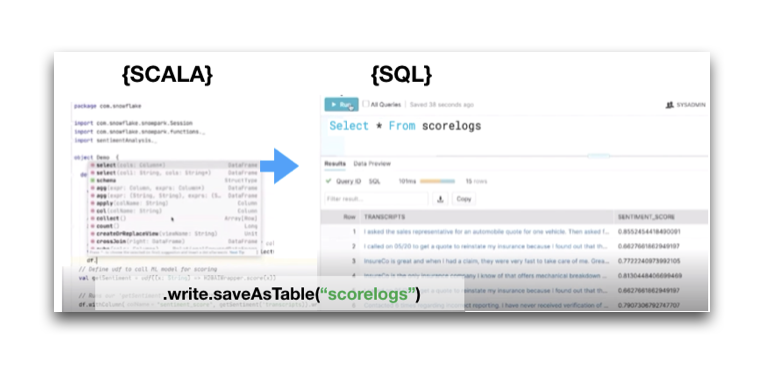
זוהי הכרזה דרמטית מכיוון שכל ארגון יוכל לקחת את הקוד של ה-Data science ולהרחיב/להעשיר באמצעותו את המידע ישירות בתוך סנופלייק. שימו לב לתמונה הבאה מהדמו בה פיתוח של פונקציה ב-scala זמין לתחקור בסנופלייק. הטבלה scorelogs אינה טבלה בסנופלייק, אלא מימוש של טבלה באמצעות קוד סקאלה. יכולת זו תהיה זמינה בפייתון, ג׳אווה וסקאלה, כך שכל ארגון יוכל לממש זאת בשפה המקובלת בארגון.
Data Governance
שימו לב למהפכה הבאה בתחום ההרשאות! ביוני האחרון סנופלייק הציגו את ה-Dynamic data masking, יכולת להצפין ולמסך תוכן של עמודות עם מידע אישי רגיש. זוהי למעשה יכולת של Column level security. בכנס קבלו את ה-RLS! סנופלייק משיקה Row level security מובנה בתוך בסיס הנתונים! כך שכל משתמש רואה רק את הרשומות שהוא מורשה לראות!
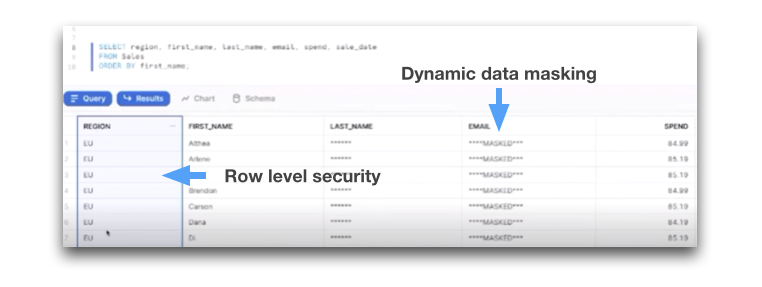
יכולת זו מאפשרת את ניהול הגישה לכל מקורות הארגון ממקום אחד. בין אם המידע בקבצים, ב-Storage ב-S3 או ב-External tables, הכל מנוהל ממקום אחד. ובאמצעות יכולת הרפליקציה בין החשבונות (חוצה ספקי ענן וחוצה regions) ניתן בקלות לאכוף את ה-Policies האלו לכלל הארגון.
מנהל המוצר עוד רמז כי אפשר לצפות לזיהוי אוטומטי של עמודות PII (Personal Identification Information) וליכולות הצפנה של המידע בצורה מובנית.
בקיצור נושא ה-Data governance ו-Complience נמצא גבוה בסדר העדיפויות.
Platform Performance & Capabilities
ביצועים
סנופלייק ממשיכים לשפר את מנוע ה-SQL המהיר שלה. מבחינת ביצועים, ע״פ השוואה בין שאילתות שרצו באוגוסט 2019 לעומת אותם שאילתות שרצו באוגוסט 2020, 72% מהשאילתות שעברו קומפילציה בפחות משניה, השתפרו ביותר מ-50%.

שיפורים אלו מורידים את הצורך בזמני עיבוד ולמעשה בסופו של דבר גם חוסכים כסף ללקוחות.
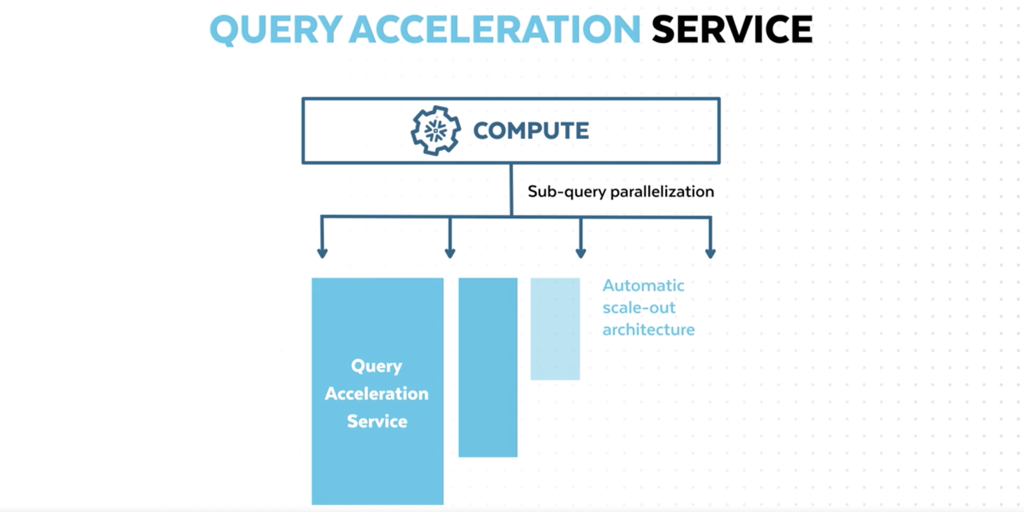
חדש! שירות להאצת שאילתות
עד כה היו בסנופלייק שתי אפשרויות, Scale out כלומר הרחבה של מספר ה-Clusters שנותנים מענה לשאילתות ו-Scale-up שהיא הגדלה של ה-Cluster שמריץ את השאילתות. אך בשני המקרים, שאילתא גדולה ככול שתהיה, תרוץ על Cluster אחד בלבד (Cluster יכול להכיל מספר שרתים). סנופלייק מכריזה על שירות חדש, שירות האצה לתתי שאילתות (Sub queries)! כך ששאילתא אחת המכילה מספר Join-ים ותתי שאילתות תוכל לרוץ במקביל על יותר מ-cluster אחד. מה שיביא לשיפור דרמטי של הביצועים של שאילתות גדולות. אלו ללא ספק בשורות מעולות ושוב מדגישות למה אנחנו כמיישמים צריכים להימנע מכתיבה לטבלאות ביניים וטבלאות עזר, נזכיר שמומלץ להשתמש ב-CTE עם With כדי לתת למנוע האופטימיזציה לעשות את שלו. בעיקר כאשר מדובר בשאילתות מרובות שלבים.
בקרוב גם Unstructured data
עד כה בכל ההרצאות וההדרכות הסברנו שסנופלייק זו תשתית דאטה, לא משנה באיזה פורמט, העיקר שיהיה דאטה, כלומר מובנה או מובנה למחצה, אך תמונות וקבצי PDF היו לחלוטין מחוץ לתחום ואותם היינו ממליצים לאחסן ב-Storage בענן בו אתם משתמשים. לא עוד, סנופלייק מודיעה כי בהמשך תהיה תמיכה גם בקבצים לא מובנים כגון תמונות וקבצי PDF (וכל סוג אחר). יחד עם היכולת הקודמת של Snowpark אתם יכולים כבר לדמיין לאן אפשר לקחת את זה. תהליכי עיבוד תמונה, קריאה ל-API-ים חיצוניים ועוד אין סוף Use-cases והכל בפשטות והקלות של סנופלייק. אז תתכוננו להריץ SQL גם על תמונות.
Vision.bi
Vision.bi גאה להיות שותף ELITE של סנופלייק ולהביא לכם את כל התוכן בפשטות ובעברית. עם נסיון של מעל 40 פרויקטים מוצלחים בשלוש שנים האחרונות אנחנו מספקים ללקוחות שירותי פיתוח ייעוץ וליווי מהמקצועיים ביותר בתחום. אם אתם מעוניינים בדמו על Snowflake מוזמנים לשלוח לנו מייל ל- info@vision.bi או לחוץ על כפתור הצור קשר מימין למטה, ונשמח לקבוע פגישת היכרות להצגה של בסיס הנתונים שללא ספק מתווה את הדרך לעתיד בתחום הדאטה.