
מהו Data Lake, מה מטרתו, במה הוא שונה מ-Dwh, מתי וכיצד לבנות אותו שישרת את צרכי הארגון ובאיזה כלים?
אם נלך לפי ההגדרה היבשה של Data Lake כפי שהיא מופיעה בויקיפדיה
“A data lake is a system or repository of data stored in its natural/raw format,
... usually a single store of all enterprise data including raw copies of source system data and transformed data used for tasks such as reporting, visualization, advanced analytics and machine learning.
... can include structured data from relational databases (rows and columns), semi-structured data (CSV, logs, XML, JSON), unstructured data (emails, documents, PDFs) and binary data (images, audio, video). “
ובתרגום חופשי זוהי סביבת אחסון מרכזית, הכוללת עותקים של המידע מכלל המערכות התפעוליות/ארגוניות, העברתם דרך תהליכי עיבוד (לפחות את חלקם), לצורך מתן שירות לדוחות / ויזואליזציות, תחקורים מתקדמים ו-ML. דאטה כמובן יכול להופיע בפורמטים רבים ולא רק כמידע מובנה.
Data Lake לא נועד רק לארגונים גדולים. זהו עקרון תשתית מידע שצריך להיות קיים בכל ארגון המחבר יותר משני מקורות נתונים.
ההגדרה הנ״ל מאד פשטנית, בסוף צריך לתרגם אותה לפרקטיקה ולתוצרים שנותנים ערך לארגון. בפוסט הזה אנסה לתרגם את התאוריה לפרקטיקה, למקד את מטרות ה-DL ולתת את העקרונות המנחים במימוש סביבה כזו בארגון. לבסוף גם ניתן מספר כלים ואפשרויות למימוש, כולל מספר אפשרויות מודרניות.
אתחיל בכך שלא מדובר באתגר טכנולוגי! Data Lake הוא אתגר עיסקי וצריך להימדד כמעט ורק לפי הערך והתועלת שהוא מביא לארגון. חישוב ROI ל DL הינו מאתגר ולא פשוט, אך יש לשאוף למדודו אותו ולהגדיר יעדים עסקיים ברורים בהקמת התשתית…
נמשיך בזה שלא צריך להבהל מהמונח Data Lake, הרבה מהעקרונות שלו הם אותן עקרונות כמו בהקמת תשתית מידע רגילה. פעם קראנו לזה ODS, Mirroring ושמות קוד דומים כדי לומר אותו דבר, מאגר המרכז את כל מערכות המקור והמידע הרלוונטי. יש למאגר הזה מטרות ועקרונות ברורים ועליהם מיד נרחיב. אמנם העקרונות לא השתנו, אך העולם בו אנו חיים השתנה. אנחנו נמצאים בעידן התפוצצות ה-Data. אם בעבר פתרנו את ה-ODS בשרת נוסף, בבסיס נתונים נוסף או ב-Storage נוסף, כיום אנחנו כבר במקום אחר. כיום נדרשת לרוב טכנולוגיה אחרת, שונה, סקיילאבילית, כזו שזול לשמור בה את כל המידע מבלי לאבד את היכולת להפיק ממנו תועלת. והמידע כבר לא טבלאי וגם לא מגיע רק מתוך המערכות הפנימיות של ארגון.
מיקום ה-Data Lake, תרשים ארכיטקטורה לדוגמא (מקור: אתר Vision.bi):

מטרות ה-Data Lake
מטרתו הראשונה של ה-Data Lake, היא ״איגום״ המידע, או במילים פשוטות שמירת ה-raw data בצורה כזו שהיא פשוטה וזמינה לניתוח כולל הצלבת מידע ממערכות שונות. היכולת לעשות Join בין נתונים ממערכות שונות היא היכולת הבסיסית ביותר והיא הבסיס להכנת המידע בשלבים הבאים.
מטרתו השניה היא ניתוק מהמערכות התפעוליות ושמירת היסטוריה. בין אם אלו מערכות פנים ארגוניות או מערכות חיצוניות (API), הן לא מיועדות לשמור היסטוריה ולרוב טעינת היסטוריה (טעינה חוזרת של כל הנתונים) הינה יקרה ודורשת מאמץ.
*אם מנתחים כיום מה הביא ל״התפוצצות״ עידן ה-Hadoop, אלו שתי הסיבות המרכזיות. היכולת לשמור את המידע ולעבד אותו בעלויות שלא היו מוכרות עד אותה נקודת זמן. בעידן שחברות עוד חששו לצאת לענן, הטכנולוגיה היחידה שהיתה זמינה בידי ה-IT היתה Hadoop.
שלוש - עיבוד ראשוני לצורך הצלבת/השלמת מידע. בסביבת ה-Data Lake המידע נשמר כפי שהגיע מהמערכות התפעוליות. במידה והמידע אינו שימושי כמו שהוא נבצע בו התאמות בסיסיות כמו הוספת עמודות מקשרות / טבלאות תרגום וכד׳. לעיתים נעשה גם שינוי פורמט של הנתונים לצורך חסכון במקום/עלויות למשל החלפת קבצי Json ב-Parquet. אך לא נכניס בשלב זה לוגיקות מורכבות, לוגיקות עסקיות ואחרות היכולות ל״סכן״ את יציבות המערכת או את איכות הנתונים.
ארבע - שמירת שינויים לאורך זמן ויצירת מפתחות מורכבים. שני תהליכים טכניים המוכרים כ GK - Generated Key ו- CDC - Change Data Capture. הראשון ליצירת מפתח פשוט במקרים בהם מפתח הטבלה מורכב מארבע עמודות או יותר, והשני לשמירת שינויים במידע שאינם נשמרים במערכות התפעוליות, למשל שמירת שינויים בשיוך עובד למחלקה לאורך זמן. באוניברסיטה עדיין מלמדים שאלו השלמות הנעשות בשכבת מחסן הנתונים, אך כבר לפני עשור העברנו אותם לשכבת ה-ODS כי מצאנו בזה ערך רב ברמה הטכנית וברמת פשטות הפתרון - מנתק את התלות בין התהליכים במחסן הנתונים.
עקרונות בסיסיים
אלו הם העקרונות הבסיסיים עליהם יש לשמור בהקמת Data Lake ולמעשה בהקמת כל מערכת מידע. חשוב לגבש אותם בהתחלה וליישר קו עם כל השותפים בהקמת התשתית, שכן זוהי תשתית ארגונית ונכס שצריך לשרת את הארגון להרבה שנים. תתאימו את העקרונות לארגון שלכם, הם כלליים, אבל נכתבו ביזע ודמעות :-)
פשטות - העקרון החשוב ביותר אותו אנחנו חוזרים ואומרים בכל הזדמנות: מה שלא יהיה פשוט - פשוט לא יהיה. שינוע נתונים ותהליכי ETL או ELT זה לא מדע טילים, אלו תהליכים פשוטים מאד המבוססים על מתודות קבועות. אם אתם מוצאים את עצמכם שוברים את הראש על לוגיקה מסויימת בתהליך טעינה אתם כנראה צריכים לעצור ולחשב מסלול מחדש. בהחלט בכל פרויקט יש אתגר ובכל פרויקט יש את התהליך הזה שדורש לצאת קצת מהקופסא, זה גם מה שהופך את התחום למעניין כל כך, אבל זה צריך להיות בתהליך אחד או שניים גג. אם זה קורה לכם בכל תהליך, או שֿאתם מרגישים שאתם בונים מגדל קלפים שאם רכיב אחד לא יעבוד כל המערכת לא תעבוד אתם בבעיה.
שפות תכנות - הדרך בה תממשו את הפתרון והכלים שתבחרו ישפיעו על הארגון לטווח הארוך, לכן תשקיעו בזה מחשבה. לא מעט ארגונים בוחרים את הכלים לפי הידע הזמין כרגע בצוות, ואכן ראינו עשרות מקרים של תהליכי טעינה כתובים ב-Java או אנשי ה-R&D שבוחרים ספארק. אלו כמובן טכנולוגיות מצויינות ויודעות לפתור הרבה אתגרים, אבל אלו Skills מורכבים יחסית ולא תמיד עוזרים לשמור על עקרון הפשטות. אם כל הרחבה של צוות הדאטה כוללת גיוס מפתח R&D, זה מאד יקשה בהמשך על גידול הצוות. שלא יצלבו אותי אנשי R&D (אני גם כזה), אבל אנשי R&D אינם אנשי דאטה. לעומת זאת, אנשי SQL לרוב באים עם יכולות גבוהות של הבנת הנתונים, הבנת תהליכי שינוע והכל בשפה פשוטה מאד. אז אם בחרתם ״להפיל״ את המשימה על אנשי R&D חשוב להעביר אותם את ההכשרה הנדרשת.
כלים - תפתרו בעיות עם הכלים הנכונים והפשוטים ככל הניתן. תמיד ישנם שיקולים האם להשתמש בכלי מדף או בפיתוח עצמי. נשמור בסוף הרחבה על כלים, אבל חשוב לבחון את הכלים הקיימים בחוץ, רוב הבעיות איתן תתמודדו כבר נפתרו, לא צריך להמציא את הגלגל.
ניתוק תלויות - ה-Data Lake היא שכבה תפעולית / אופרטיבית עצמאית. במקרים בהם ההפרדה בין ה-Data Lake לבין ה-DWH ברורה עקרון זה נשמר מכורח המציאות (למשל האחד ב-Hadoop השני ב-MSSQL). אך בסביבות בהן שתי השכבות האלו מבוססות על אותה טכנולוגיה, למשל Big Query או Snowflake , ההפרדה הזו חייבת להתבצע באופן לוגי, אין ליצור כל תלות בין שכבות המידע, מכיוון שאלו מערכות שונות. לעיתים זה נראה מוזר ומאולץ שלצורך יצירת יישות מידע פשוטה יוצרים שני תהליכי טעינה, האחד ל-Data Lake והשני ל-Dwh. אבל ההפרדה היא הכרחית לתפעול. כדי להקפיד על זה תחליטו מהיום הראשון בפרויקט שה-ODS יתוזמן להתעדכן כל חצי שעה וה-Dwh כל שעה, ברגע שתעשו זאת הגבולות יהיו מאד ברורים.
רציפות הטעינות - מקורות הנתונים שונים ברמת העדכניות שלהן. מידע מקמפיינים בפייסבוק שונה מעדכונים של ביקורים באתר או ממידע של מערכת פנימית. ולכן כל תהליך חייב להיות עצמאי ומתוזמן בקצב המתאים לו. ניתן לאגד מספר תהליכים שירוצו / יתוזמנו יחד אך אין ליצור ביניהם תלות.
סטנדרטיזציה - בתחילת הדרך חשוב לקבוע את הסטנדרטים הבאים:
א. סטנדרט שמות - טבלאות, עמודות , תהליכי טעינה וכד׳. המלצה - טבלאות ועמודות ישמרו תחת סכמה של מערכת המקור. כלומר לכל מערכת מקור תהיה סכמה ב-Data Lake ושמות הטבלאות ישמרו עם אותן שמות כמו במקור. כמו גם העמודות.
ב. עמודות ניהול - עמודת תאריך יצירה ותאריך עדכון על כל רשומה ב-Data Lake
ג. תהליכי טעינה - מהם ה-Templates לטעינת נתונים. איך קוראים מידע מהמקורות (Increment, Full), איך כותבים לטבלאות היעד (Insert, Append, Overwrite, Switch) וכו׳
ד. לוגים - כל תהליך חייב לכתוב התחלה וסיום, מומלץ כמות רשומות שהוכנסו, כמות רשומות שעודכנו.
ה. מבנה תיקיות - כאשר השכבה הראשונה בפתרון מבוססת על Storage (כגון S3, GCS), חשוב מאד לקבוע מבנה תיקיות חכם, כזה שיאפשר קריאה נוחה וריצה הגיונית עם האובייקטים ב-Storage, אם למשל תזרקו את כל הקבצים לתיקייה אחת זה יקשה מאד לקרוא את הנתונים בצורה אינקטמנטלית. תשמרו כל טבלה לפי שנה/חודש/יום (לעיתים גם שעה) ולעיתים תרצו ליצור מחיצות לכל לקוח לצורך אינדוקס טוב, כל ההחלטות הללו יהיו קריטיות כשתרצו לחבר כלי תחקור מעל האחסון.
טעינת היסטוריה - כל נתוני ההיסטורי יעברו באותו pipe של התהליכים השוטפים. לא צריך לפתח תהליכים שונים לצורך ייבוא ההיסטוריה, צריך פשוט לתכנן נכון את התהליכים השוטפים שידעו לטפל ב-Batch Size. ולא להניח שהמידע רק מתווסף לסוף.
יש עוד הרבה טיפים כמו תבניות של זיהוי אוכלוסיות, פרטישנים מלוכלכים ועוד, לא נכנס לכולם.
בחירת כלי האחסון / בסיס הנתונים
נתחיל במהם לא כלי Data Lake:
בסיסי נתונים רלציוניים רגילים - כדוגמא MSSQL או אורקל. לא DL מכיוון שהם אינם סקיילאביליים. לא יכולים לשמור Raw Data, לרוב לא מתאימים לתחקור מידע Semi Structure. גם אם כיום נראה שיש לכם בארגון ״מעט נתונים״, תמיד יגיע מקור המידע הזה שיצריך כח עיבוד משמעותי יותר ויכולות תחקור בקצבים גבוהים יותר.
בסיסי נתונים NoSql - כדוגמת MongoDB או Elastic Search. לא DL, אמנם מאפשרים לשמור Raw Data אבל אינם מאפשרים הצלבת מידע בין מקורות נתונים ואינם יכולים לשמש כתשתית תחקור אמיתית (חסרי יכולת בסיסית של Join).
בסיסי נתונים מסוג MPP - כדוגמת Vertica, Netezza או Redshift - לא DL, שמירת Raw Data יקרה מידי, מוגבלים ב-concurrency (לרוב תהליכי עיבוד הנתונים מכבידים על משתמשי תחקור הנתונים). מוטב לשמור את הכלים הללו לתחקור מידע ולעשות את העיבוד לפני שלב הטעינה ל-MPP.
*בתחום זה מתחילים לראות שילוב של MPP עם טבלאות External Tables כמו Redshift Spectrum או Vertica EON, אך לערכתי זו רק תחילת הדרך ביכולת להקים DL משמעותי הכולל עיבוד מידע.
אז מה כן? כיום יש מספר אלטרנטיבות:
האלטרנטיבה הוותיקה Hadoop On-Prem
הקמת תשתית ארגונית. מבוססת על שמירת המידע ב-HDFS, עיבוד המידע ב-Hive או Spark ותחקור ב-Hive, פרסטו, אימפלה וכו׳. פתרון ותיק ןעובד, מבוסס טכנולוגיית Open Source ומאד מקובל. פתרון זה פרץ בסביבות 2012-13, נמצא כיום בהרבה ארגוני אנטרפרייז שמשתמשים בו לצורך הורדת עלויות אחסון נתונים. מידע באורקל וטרה דאטה נהיה יקר והדופ היה הפתרון המושלם לצורך המשימה. חסרונות - פתרון יקר תחזוקתית, מורכב, דורש Skills גבוהים, סקיילאבילי במידה גבוהה אך דורש לרוב הרבה תחזוקה של תהליכים כדי לנהל נכון את המשאבים והזכרון.
הצניחה של מניית Cloudera ועוד לאחר המיזוג עם Hortonworks המתחרה הגדולה, אמור להדליק נורה אדומה לכל מי ששוקל להיכנס לטכנולוגיה בימים אלו.
האלטרנטיבה הנפוצה - תשתית אמזון
כמו כל דבר טוב שפרץ ב- On-Prem, אמזון זיהתה ואפשרה את אותו פתרון על התשתיות שלה. כאן האחסון מבוסס על S3 במקום HDFS, והעיבוד נעשה גם כן ב-Hive או ב-Spark דרך שירות ה-EMR. בהמשך אמזון שיחררה את Glue, שירות מנוהל המאפשר להריץ עיבוד קבצי ב-S3 ואת Athena, שירות Presto מנוהל המאפשר לתחקר את המידע. שני פתרונות נוספים הם Redshift, פתרון ה-Dwh ו- Redshift Spectrum פתרון External Tables מעל S3.
כיום הייתי אומר שזה ה-Stack הנפוץ בעולם, היתרונות הם שהכל מבוסס על אותה סביבת אמזון. החסרונות הם בכמות הכלים השונים אותם צריך ללמוד ואותם צריך לנהל. לצורך אחסון S3 הוא ללא ספק פתרון מושלם. אך כשמגיעים לתחקור לכל אחד מהכלים של אמזון יש חסרון באיזור אחר. יהיו מקרים בהם זה יענה בדיוק על הצורך ויהיו מקרים בהם תגיעו למגבלות של כל רכיב די מהר.
מיקרוסופט Azure
באיחור קל מיקרוסופט הצטרפה לחגיגה, אך ללא ספק סוגרת הכי מהר את הפער. לכל הפתרונות של אמזון יש מקבילה באז׳ור. S3=Azure Blob Storage ו- Azure Data Lake (כן ניכסו לעצמם את השם),
EMR=HdInsight, Athena=Azure polybase, Redshift=ADW וכו׳. בגדול היתרון המרכזי של אז׳ור הוא בעיקר בעולמות האנטרפרייז. בעיקר כי מיקרוסופט כבר נמצאת בכל הארגונים האלו והחדירה אליהם יותר קלה מלאמזון למשל. עם זאת הרבה ארגונים הולכים בכיוון הענן ההיברידי ולאו דווקא עם ספק ענן בודד.
גוגל
גם לגוגל כמובן יש מקבילה לכל רכיב. האחסון הוא Google Cloud Storage ויש רכיבים נוספים כמו Data Proc במקום ה-EMR וכו׳ אבל דווקא כאן מתחיל השינוי המעניין שרואים בשנים האחרונות. וגוגל היו הראשונים שהתחילו אותו כבר ב-2013 עם שחרור ה-Big Query, במקום ניהול שרתים, זיכרון, עומסים ואינדקסים, גוגל שחררו בסיס נתונים מנוהל (Full Managed) שמפשט מאד את כל הפתרון, במקום מגוון רחב של פתרונות, בסיס נתונים אחד שיודע לעשות 85% ממה שנדרש מ-DL. תמיכה ב-Semi Structure ויכולת להריץ תחקור עם ביצועים גבוהים על טרות (Tb) של נתונים. ואכן מהיכרות עם המון ארגונים, תמיד רואים פתרונות באמזון המורכבים ממספר רחב של פתרונות ומצד שני ארגונים בגוגל שהקימו תשתיות מידע שלמות המבוססות רק על BQ. יהיה מעניין לראות את יחסי הגומלין שיווצרו בין BQ לסנופלייק עם כניסתם ל-GCP.
סנופלייק - ה-Data Lake המודרני.
אם ב-BQ ניתן לעשות הכל בבסיס נתונים אחד ומנוהל שמוריד את עלויות התחזוקה ומפשט את הפתרון, הגיע הזמן שתכירו את סנופלייק (Snowflake) המאפשר את אותה יכולת ממש אבל על כל העננים, ואפילו בצורה מתקדמת יוץר בהרבה מהמקרים. ללא ספק הכוכב הזוהר החדש חברת ה-SAAS הצומחת בעולם בכל הזמנים, הגיע לשווי חברה של 3.5 מיליארד דולר תוך 3-4 שנים בלבד. סנופלייק, כמו BQ הוא בסיס נתונים המאפשר לשמור נפחים בלתי מוגבלים, עם יכולות עיבוד גבוהות וביצועים מזהירים והכל בשירות מנוהל. אמנם הוא לא מקיף כרגע 100% מהצרכים של DL, כמו אחסון קבצים בינריים או הרצת מודלים של Machine Learning, אבל מאפשר אחסון נתונים בלתי מוגבל, תחקור ועיבוד כולל Join-ים של טבלאות עצומות (ELT) ותמיכה בכל סוגי המידע (Structure & Semi Structure). אם נלך לעקרון הפשטות, הוא מיישם אותו ברמה השלמה ביותר, מכיוון שמדובר בשירות אחד המכיל הכל וב-Skills הבסיסיים ביותר - SQL המוכר לכל אנשי הדאטה. פתרונות משלימים של Machine Learning יש על כל אחד מהעננים בהם הוא מתארח והחיבור אליו קיים בכל הפלטפורמות.כאמור רץ על כל אחד מהעננים (אמזון, אז׳ור וגוגל עד סוף 2019).
מגוון האפשרויות בעננים השונים
*יתכן שיש עוד מוצרי נישה, אלו המוצרים אותם אנחנו פוגשים ברוב המקרים
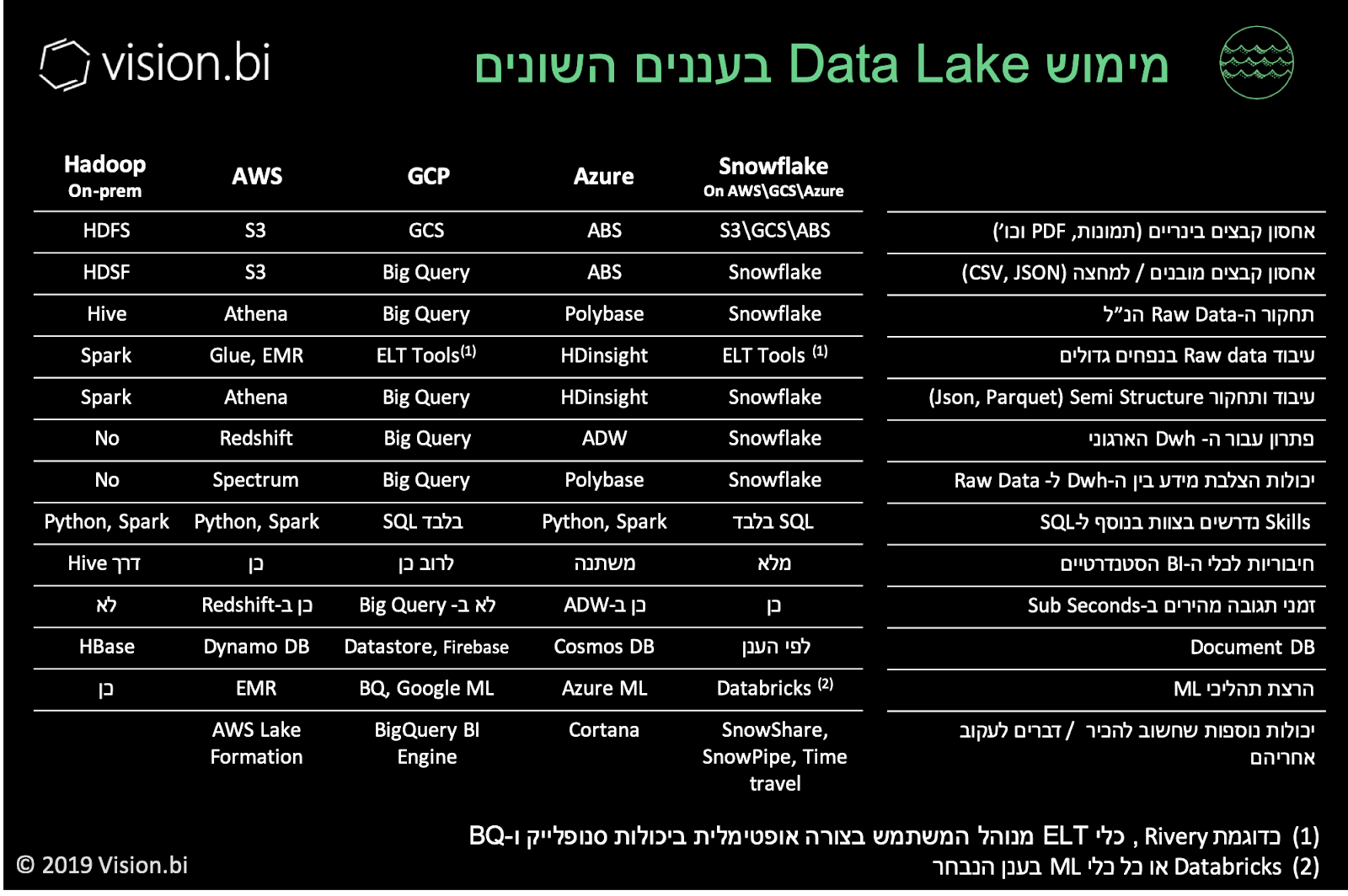
לסיכום - אם הענן הוא לא אופציה עבורכם מוטב שתחכו שזו תהיה אופציה או שתערכו להשקעות רבות. רק הקמת התשתית תדרוש סכומים גבוהים מהיום הראשון וחישוב ה-ROI יהיה מאתגר במיוחד.
אבל אם הענן הוא אופציה כיום אני ממליץ לבחון פתרונות מנוהלים כאלטרנטיבה מובילה, רוב הסיכויים שתמצאו את סנופלייק או Big Query (כאשר לסנופלייק יש אף יתרונות במימוש DWH) בתור הפתרונות שיתנו לכם מענה על כל הצרכים לשנים הקרובות.
שניהם פתרונות מנוהלים (Full Managed), אינם דורשים צוותי תשתיות ו-DevOps, בעלי מודל תמחור הוגן (לפי שימוש) ויכולים גם לשמש כ-Dwh בהמשך, יתרון דרמטי על פני פתרונות אחרים.
כלים נוספים תוצרת הארץ שאתם חייבים להכיר
כמות הכלים הקיימים בתחום הזה היא אין סופית. מצורפים 4 מוצרים שהם תוצרת כחול לבן (*שניים מהם יצאו מ-Vision.bi), שעושים חיל בעולם ומן הראוי שנכיר אותם בארץ :
- ריברי (Rivery) - מוצר Data pipeline מנוהל המתאים לטעינת מקורות נתונים ל-Data Lake ועיבוד נתונים ב-ELT בתוך ה-Data Lake. ריברי תומכים בכל בסיסי הנתונים כמקור ובמעל 70 מקורות נתונים חיצוניים כדוגומת פייסבוק, SalesForce כך שצוות הדאטה לא צריך להתעסק עם כתיבת תהליכי טעינה מ-API. *גילוי נאות - ריברי הוא מוצר שיצא מ-Vision.bi ובאותה נשימה נוסיף שהוא נכתב על ידי אנשי מקצוע שצמחו מהתחום
:-)https://rivery.io - אטיוניטי (Attunity) - מוצר רפליקציה ב-Stream מבסיסי נתונים שונים לתוך ה-Data Lake. מתאים בעיקר לארגוני אנטרפרייז. החברה נרכשה לאחרונה ע״י Qlik.
https://www.attunity.com/ - סקיופיי (SecuPi) - מוצר להצפנת מידע לפני העלאה לענן ופענוח המידע ב-On-Prem. מתאים לארגוני אנטרפרייז או סטארטאפים גדולים בהם נושא ה-GDPR קריטי.
https://www.secupi.com/ - קוויליאפ (quilliup) - מוצר בקרת תהליכי שינוע. בדיקת שלמות הנתונים, בחינה שהנתונים עברו כמו שצריך בין שכבות המידע והמשתמשים צורכים מידע אכותי המתאים למקורות. מתאים בעיקר לארגוני אנטרפרייז. *https://quilliup.com
ושום מילה על Streaming
אי אפשר לסיים לדבר על Data Lake מבלי להזכיר Streaming. אז כן, יכולות Streaming הן בהחלט חשובות, ויש Use Cases שלא נתנים לפתרון ללא Streaming וקבלת החלטות בזמן אמת. אבל חשוב לומר שאלו פתרונות יעודיים הבאים לפתור צורך נקודתי. על פי רוב תהליכי ה-Streaming יצטרכו לקבל החלטות על בסיס מידע מעובד והמידע המעובד הזה על פי רוב מחושב ב-Batch. ואם נחזור לעקרון הפשטות, מה שלא יהיה פשוט - פשוט לא יהיה, ובמקרה של Streaming לרוב אלו פתרונות שדורשים יותר תחזוקה ויד על ההדק ולכן הם צריכים להיות בשימוש במקומות הנדרשים בלבד.
לקריאה נוספת על סנופלייק כ-Data Lake: